Title here
Summary here
April 18, 2012 in Systems5 minutes
I’m currently working with a relatively large Cisco UCS installation. Initially, the system was installed and brought up to relatively recent levels of firmware, but a mismatch in the way that the firmware packages were set up in various sub-organizations on some of the UCS systems caused some of the blades to retain the old version of firmware on the M81KR adapters and the CIMC controllers.
Due to the scope of the installation, I wanted to ensure that the blades were able to continue operating while I made my changes. I have ensured that the maintenance policy that is set on each service profile (and templates) is set to “user-ack”, meaning that any change that is applied to a service profile (i.e. firmware packages) will NOT reboot the blade immediately if a reboot is required - instead it will notify me that I need to acknowledge the change, and will reboot blades as I select them.
I spent a lot of time going through every possible scenario for upgrade procedures, and put both the UCS system and the Cisco upgrade documentation to the test. I had the ability to designate two blades for testing, and I have set them up in their own dedicated TEST sub-org. All of what I’ll be discussing in this article will be done within that sub-org.
First, I needed to get the test blades back to the old firmware, since they happened to have a working firmware package attached at the time. In order to do this, I had to manually change the firmware version within “firmware management”, which required that a firmware package is not attached to the service profile. Detaching the host and management firmware packages from the service profile template did not cause any blades to reboot.
Once detached, I unchecked everything in both packages, to ensure that they would be blank when I re-attached them. As expected, nothing happens.
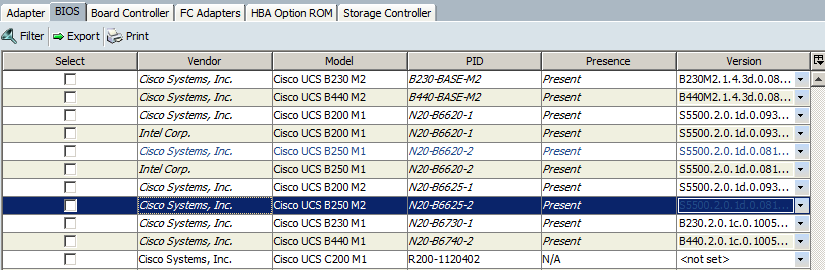
I then went into firmware management, and manually set the startup version from 2.0(1s) to 1.4(3q). I ensured that “set startup version only” at the top of this window was checked. Applying these changes caused a “reboot” message to appear next to the CIMC controller:

I’m not _terribly _worried about this since I will not be affecting production blades in this way - this is only to simulate servers that have not been given the new code yet. However, after reading this in the Cisco 1.4 to 2.0 upgrade documentation (page 32):
The activation of firmware for a CIMC does not disrupt data traffic. However, it will interrupt all KVM sessions and disconnect any virtual media attached to the server.
Since the CIMCs rebooted without any sort of acknowledgement from me, I decided to put this to the test. I tried the same firmware change that I did before, but before applying, I started a ping to the management address of ESXi, which was installed on one of these test blades:
# ping 172.16.0.11
PING 172.16.0.11 (172.16.0.11): 56 data bytes
64 bytes from 172.16.0.11: icmp_seq=0 ttl=63 time=3.338 ms
64 bytes from 172.16.0.11: icmp_seq=195 ttl=63 time=3.028 ms
--- 172.16.0.11 ping statistics ---
196 packets transmitted, 196 packets received, 0.00% packet loss
round-trip min/avg/max = 2.97/3.116/10.11 ms
As you can see, not a single ping was dropped. Also, the KVM session I was in disconnected. Seems like the system performed exactly as documented - kudos to Cisco on that one. This is confirmed if you look at the firmware status once more at this point:
(You’ll also notice that the M81KR adapters for each blade have not been upgraded yet - unlike the CIMC controllers, these cannot be upgraded while the system is active, and UCS is notifying us that a reboot is necessary to finish the job on these.)
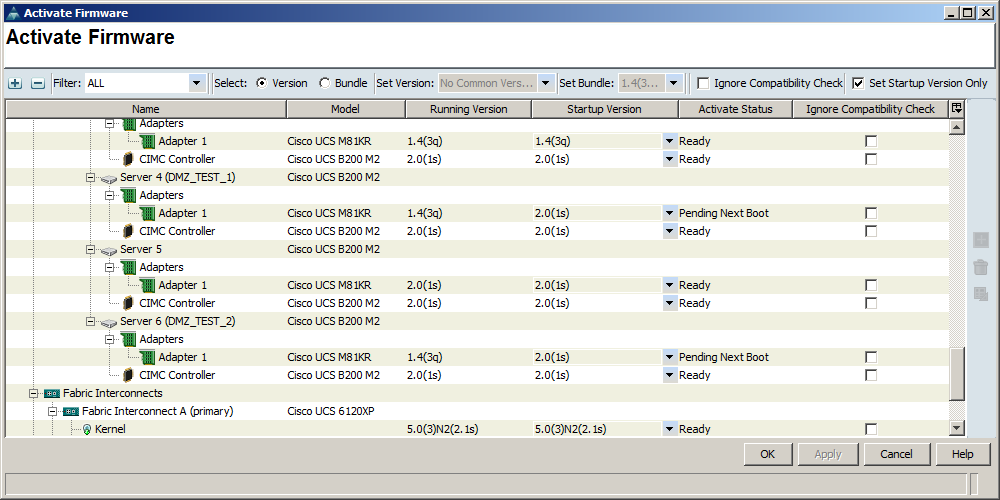
NOTE: This was only done because I checked “set startup version only”.
Now that all my test blades are on the old version of code, I can go through the motions of applying firmware packages (that are now blank), then changing the packages to include new versions of code for the M81KR adapters and the CIMC controllers.
Re-attaching the blank firmware packages may bring up this message:

Don’t freak out - this message is a minor one, though the wording could be improved somewhat to prevent the sudden surge in blood pressure it causes. It simply means that you need to set your desired BIOS version in the host firmware package after it’s attached.
The order of the following is my own preference to get the bios errors addressed so they don’t pop up later. The CIMC upgrade is accomplished via the management firmware package:
You’ll notice that when this is applied, the blades do not reboot, but they do undergo a reconfiguration as the new CIMC firmware is applied. Similar to the manual firmware change, the KVM session is disconnected, but normal VM traffic is uninterrupted.
Setting the version of the BIOS did nothing since the BIOS version was already up to date.
Next, the upgrade of the M81KRs. This should require a reboot, so the hope is that the change will trigger the maintenance policy linked to the service profiles, rather than reboot the blades immediately. A quick change to the host firmware package confirms this is the case:
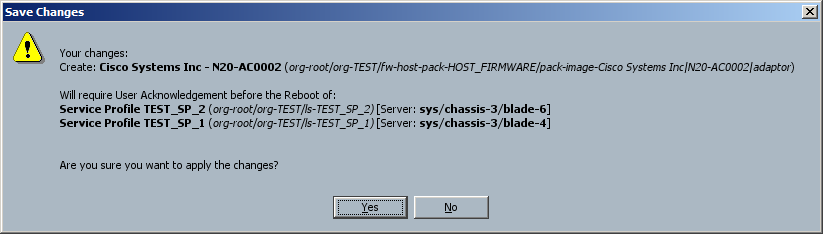
Once the blades rebooted and came back up, I upgraded the SAS controllers for the onboard storage. This also triggered a user-ack.
Now, the blades are up to date from a firmware perspective, and I know everything about what to expect as it pertains to ongoing connectivity. Going into my maintenance window, I’m now confident about the order of the changes I will make, and when to expect that I’ll have to disrupt connectivity, and when I won’t. This will allow me to acknowledge blades after I’ve vMotioned VMs off of them, meaning that - if done correctly - a full firmware upgrade can be done in UCS with zero downtime.