Title here
Summary here
January 28, 2013 in Systems13 minutes
I’m working on setting up a lab that consists of leading storage and compute products for testing, and I ran into some interesting issues with a few different things…some with respect to the way the Cisco ASA does hairpinning, as well as allowed connections in such a configuration. There were also some routing issues experienced as a result, and I want to explore my experience in all of this during this post. I encourage you to lab this up in GNS3 - you will learn a lot about the basics of TCP as well as routing. First off, the overall topology is shown below:
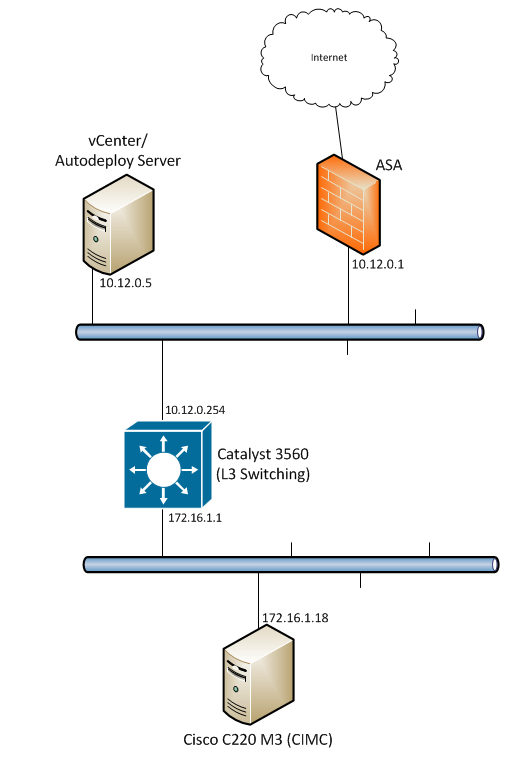
I wanted to be able to segment off a few things from the rest of the network, so I created a new subnet - 172.16.1.0/24 - and decided to use a Catalyst 3560 I had lying around as the L3 boundary for this subnet. However, the existing subnet (10.12.0.0/24) was also needed, since it was the subnet I was sitting on with my workstation, as well as another ESXi host housing vCenter with Autodeploy. My goal was multifaceted, but for the most part, since my immediate need was to set up the Cisco C220 M3 servers as ESXi hosts using Autodeploy (they did not have hard drives so this was essential), I needed TFTP to work all the way from this lab subnet back to the 10.12.0.5 host, as well as HTTP access from my workstation on the 10.12.0.0/24 subnet to the CIMC interface on the server. All that is a really complicated way of saying that I needed the two subnets to talk, unencumbered by anything beyond a single hop to the adjacent subnet.
Unfortunately, since both my workstation and the vCenter/Autodeploy server were on the 10.12.0.0 subnet, and they both required internet access, it made most sense to set their gateway to 10.12.0.1 - the address of the ASA firewall. While this is ideal for internet access, it also meant that traffic destined for the 172.16.1.0 subnet was also going to be sent to the ASA. Now - I’ve already set up EIGRP between the 3560 and the ASA, so the routes were there, but the ASA still had to look at the packets destined for 172.16.1.18 being sent into it’s inside interface, and decide which interface to send it back out of.
Since the actual destination is back out the inside interface (next hop of 10.12.0.254), it would require the traffic to go in and back out of the same interface on the ASA, known as “hairpinning”. This traffic flow is not permitted by default on the ASA, as well as the majority of other firewall vendors. So, I thought this through, and I came up with three possible solutions. They all solve the problem sufficiently, but have their caveats that I will now explore.
This solution involves directly modifying the routing table of the windows hosts on the 10.12.0.0/24 subnet to point to a next-hop other than their default gateway for the 172.16.1.0/24 subnet - namely the 3560.
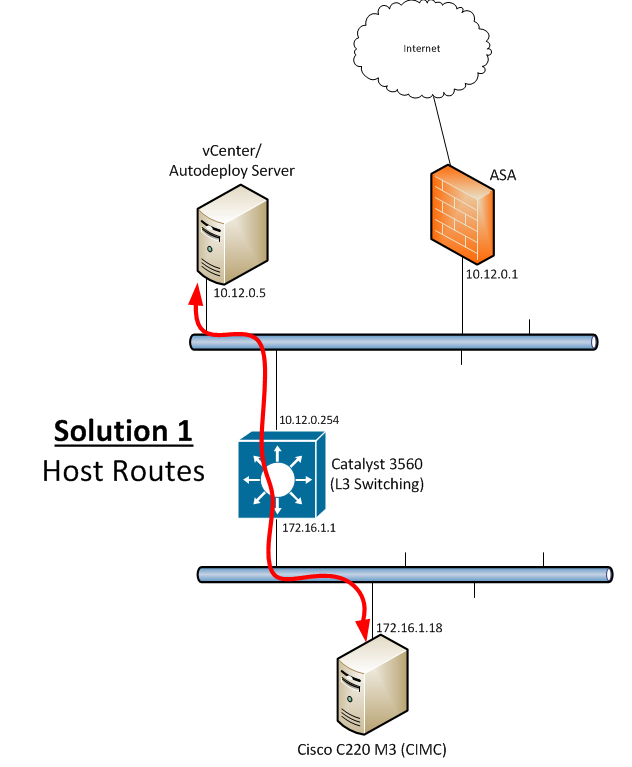
This solution solves the problem of sending traffic to the ASA in the first place by intelligently delivering traffic to where it needs to go based on subnet. In this solution, I modify the routing table of all hosts on the 10.12.0.0/24 subnet to use the 3560 as a next-hop to the lab subnet below:
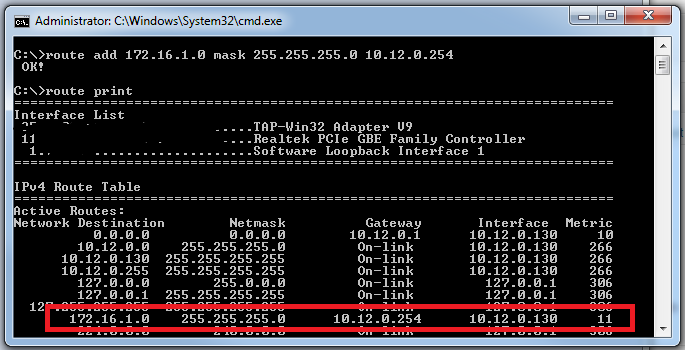
What this means, though, is that I need to touch every relevant host on this subnet. Given the fact that this is not a single host change (multiple hosts will need this fix), this is a relatively high administrative burden for a simple routing change. On top of that, I’m wary of doing anything beyond simple default routing on end-hosts, so I’d prefer to use the network infrastructure itself for this. So though this works technically, and you may prefer to go this “route” (punny) - it wasn’t for me. Solution #1 is a no-go.
The most change-heavy solution would also present me with the most granular control over what traffic goes in and out of the lab subnet. While this wasn’t a huge deal for me, it was attractive. Solution 2 involves adding a second “inside” connection (or DMZ, whatever you want to call it) so that the subnet that vCenter and my workstation were sitting on weren’t required to go to a different next-hop. By keeping the default gateway as 10.12.0.1, the ASA would receive the traffic and forward it according to the rules that I would configure out the additional routed link to the 3560:
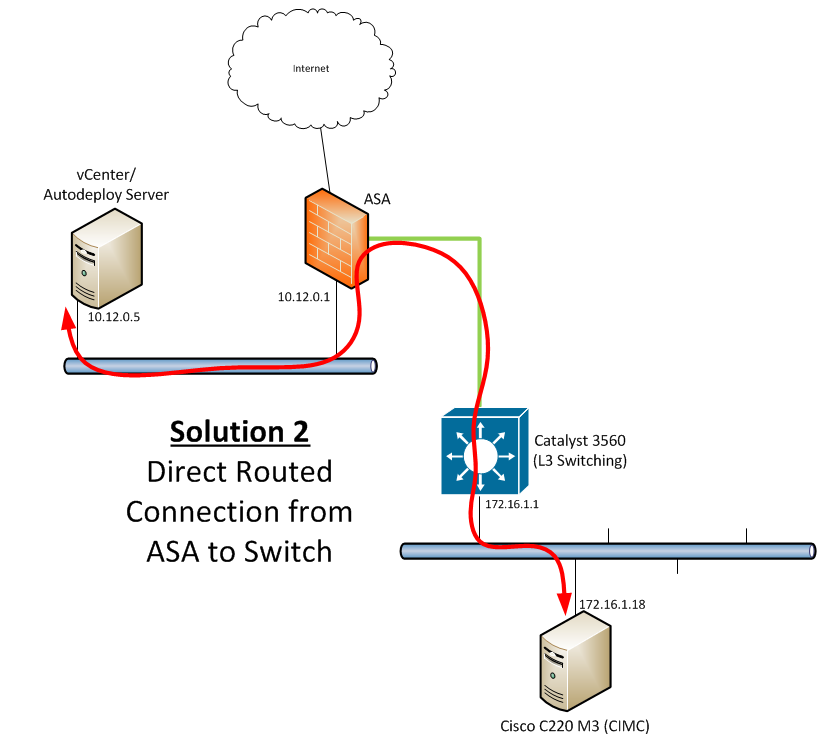
This would have been my preferred solution for many reasons, but this was a no-go for me for one very significant reason:

DOH! But it’s a lab and lab gear comes with issues like this. If you have an ASA (or other) with the licensing that allows you to do the topology shown above, it might be a good option, since it provides really good segmentation and you don’t need to do any routing magic to make it work.
I mentioned hairpinning before - instead of try to mess with host-based routing, and since we can’t change the overall physical topology because of licensing factors, we arrive at Solution 3 - using the ASA to basically redirect traffic back out the same interface in which it was received so that - although this introduces an admittedly unnecessary extra hop - the traffic goes to where it needs to go.
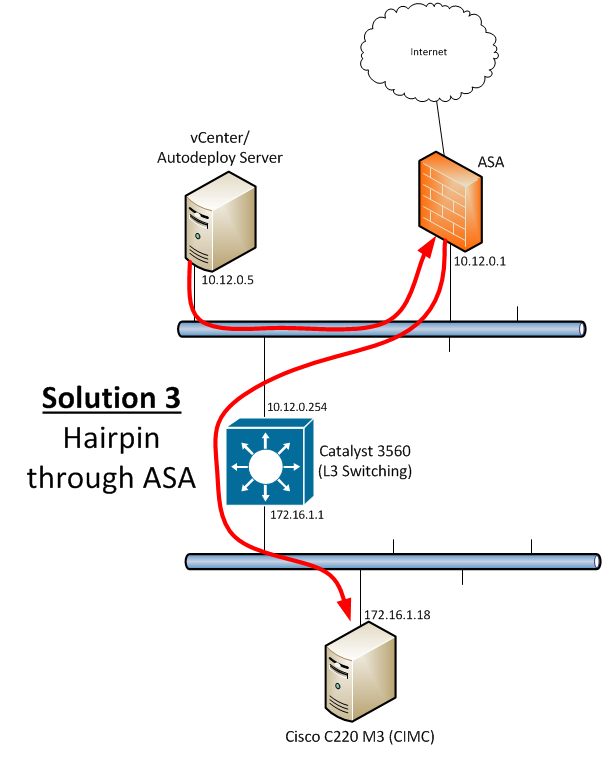
If you google “ASA Hairpinning”, you’ll be smothered with sites that explain what it is, why it’s necessary, and how to do it. Many use cases have to do with IPSec VPNs, which would require traffic to leave the same interface it was received on if it’s destined in that direction, but the walkthrough I linked to at the beginning of this post happened to be extremely similar to my situation - you have a host on a segment with two potential next-hops and you can only choose one, so the one you choose (ASA) needs to be able to recognize the traffic is destined for something else and redirect appropriately. Any walkthrough will include this command:
same-security-traffic permit intra-interface
In global configuration mode, this will allow hairpinning, or “intra-interface” traffic to be permitted back out of the interface it was received on. This is essentially just a Layer 2 header rewrite, as any router does, except that the new MAC address (in my case the mac address of the 3560 interface) happens to be on the same broadcast domain as the original MAC address, which is the MAC address of the ASA. No big deal - the switching infrastructure takes over and the packets get delivered to the 3560 regardless of having gone through the ASA.
I ran a ping to 172.16.1.18 and was greeted with 100% success! Latency wasn’t too bad either. The argument could have been made that introducing the ASA into the packet flow would be detrimental to latency, but I wasn’t seeing any more than 1-2ms, so this was more than acceptable. Time to get my DC lab up and running - after all, that’s what this has all been about! Don’t get me wrong, I love me some routing, even some firewall work (if it’s not out to kill me) but tonight was all about cloudy magical goodness, so I was itching to get into it. I opened up a web browser to 172.16.1.18 so I could get into the CIMC management portal of the server to boot and provision it as an ESXi host in my vCenter instance.
(Two minutes later) Hmm….the CIMC web page should be up and running by now. I wonder if the storage array’s web page is up. (Two minutes later) What is going on? I can ping all of the devices in my lab but nothing is loading beyond that?
This continued for a few more minutes before I sat back and thought that since one type of traffic was working but another type wasn’t, it’s very likely there’s a firewall issue. The security level of the ASA interface was 100, but just to be sure, I applied an “ip any any” (don’t do this at home) ACL in both directions on the inside interface (not the outside - I’m not suicidal) just to eliminate it as the cause of the problem. After that change, same effect - I could ping anything in that subnet correctly, and I even saw the right MAC addresses in the ARP table of the 3560, so I knew that the IP addresses were correctly assigned to the devices I intended them to be on. So what could possibly be the problem? I’ll save you the trouble and time that ensued after that - I want to point out how traffic is flowing now, given the solution (hairpinning) that we selected to solve the initial routing problem. It is true that the traffic destined to the lab subnet is hairpinning through the ASA. This was all explained in the earlier parts of the post. However, I forgot a piece of advice that has served me well time and time again, which I would also like to pass to you, in case you’ve never heard it. I consider this one of the top tenants of routing:
Always, ALWAYS remember - traffic flows in both directions.
As this thought entered my mind, I mapped out what exactly packets RETURNING from devices in the lab subnet would do if returning to a host on the 10.12.0.0 subnet. Of course, they would not need to hairpin through the ASA, since the 3560 would simply unicast them directly to the host on that subnet that the packet is addressed to! Now in this case, while the routing is being done asymmetrically as a result, it does not inherently mean that our model is broken. We should always try to avoid situations like this, but from a strict L3 perspective, this fundamentally should still work. So why does it not? It all comes down to how the ASA (and really any firewall) handles network connections, or more specifically, how it handles packets that are or aren’t part of one. During my troubleshooting, I kept seeing the following error pop up repeatedly in the ASA logs:
Deny TCP (no connection) from 10.12.0.130/17559 to 172.16.1.18/443 flags RST on interface inside
Most of us by now know that TCP operates by forming a three-way handshake between the two end devices that are attempting to establish a connection. First, the SYN packet is sent from the “client” to the “server”. Then a response from the server, in the form of a SYN/ACK, and finally, an ACK from the client indicating the connection is open.
This process is extremely relevant to firewalls - the SYN packet is the first in a flow, so the firewall uses that packet to match up against an ACL to see if the connection is permitted. If it is, the connection is established and the ASA notes the details of the connection in RAM so that additional packets in that connection are permitted without additional checks - after all, if the initial three-way handshake is permitted, the packets that flow as a result should also be allowed.
After some research into my specific problem, I came across this document on Cisco’s site. There, it states:
If packet flow does not match an existing connection, then TCP state is verified. If it is a SYN packet or UDP packet, then the connection counter is incremented by one and the packet is sent for an ACL check. If it is not a SYN packet, the packet is dropped and the event is logged.
So - knowing what we know about how the ASA treats connections, we also now have learned that packets that aren’t recognized as part of a connection are implicitly denied. So this makes sense, but why aren’t these packets recognized as part of a connection?
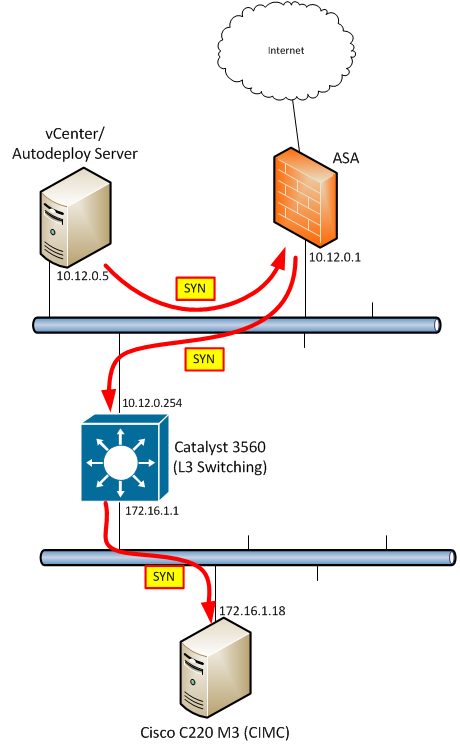
Yes, it is true that the traffic destined for the remote subnet is going through the ASA and is successfully being received by its destination. Since the ASA has seen the SYN packet, it should have already done an ACL check and verified that the initial connnection request is at least permitted. However, the ASA still has to see the entire 3-way handshake to allow the traffic flow proceed. Remember the routing rule I mentioned - always remember that there’s a return flow.
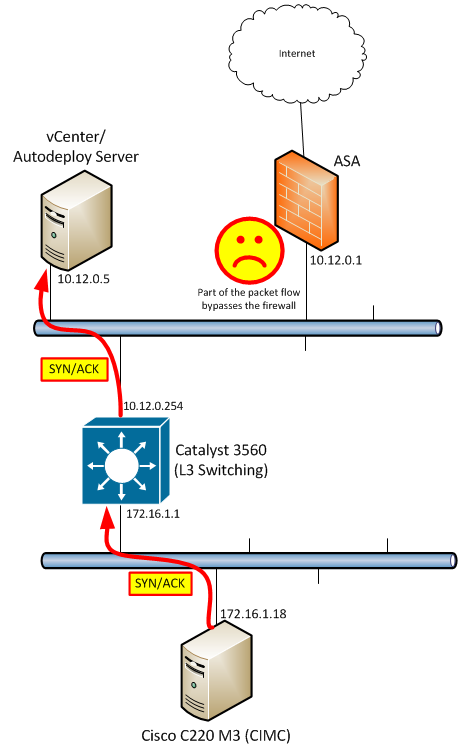
The SYN/ACK that comes back from the server DOES get to the host. However, the ASA did not see the SYN/ACK packet, since it was sent directly to the host that sent the SYN, and was not hair-pinned through the ASA. As a result, the final ACK will not make it from the originating host to the server, and the connection will not be established.
The more attentive will point out that while TCP connections weren’t working, pings were working just fine! What’s different about pings that causes them to work while TCP does not? Well, ICMP doesn’t require a three-way handshake like TCP does. My “ip any any” ACL absolutely lets single pings through and forwards them on to the destination. Since the return traffic is also delivered to the “pinging” host, meaning that the pings work just fine, even if one side of the traffic flow is taking an extra hop to get there.
So….how do we fix this? After more thought I knew that hair-pinning was still the right solution, but with this configuration, it was only being done in one direction. Thus, I had to figure out how to force return traffic to be sent to the firewall, regardless of the routing table, and regardless of the fact that the IP destination was directly on the connected interface and could simply be ARP’d for.
Thankfully, my CCNP studies were alive and well in my memory, and I knew Policy-based Routing would work for this problem. PBR is a way of statically setting a next-hop based on any number of factors, typically identified by an ACL. Typical routing is done according to what destination a given packet has. If a packet’s destination IP matches a subnet in the routing table, it’s sent to the next-hop specified. PBR takes it one step further and essentially allows you to route manually based off of any number of criteria, such as source IP address, TCP port number, etc.
It also allows you to manually specify a next-hop router to use for traffic identified in such a way. This means that the destination MAC address of packets that leave the router will be whatever that IP address resolves to in the ARP table, and this is done regardless of the destination IP address in the packet.
For us, this is great news! We can continue to ROUTE (L3) the packet to the end-host, but we will instead SWITCH (L2) the packet to the ASA for hairpinning in the return direction:
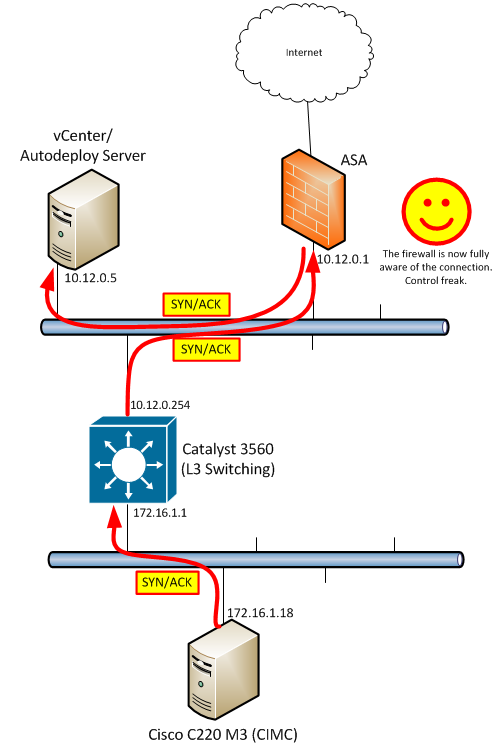
PBR is a simple matter of configuring an ACL to match the right traffic, creating a route-map to recognize this ACL and set the desired next-hop, then applying it to an interface:
DC_LAB_SWITCH(config)#access-list 101 permit ip any any
DC_LAB_SWITCH(config)#route-map FIX_ROUTING permit 10
DC_LAB_SWITCH(config-route-map)# match ip address 101
DC_LAB_SWITCH(config-route-map)# set ip next-hop 10.12.0.1
DC_LAB_SWITCH(config-route-map)#int vlan 172
DC_LAB_SWITCH(config-if)#ip policy route-map FIX_ROUTING
For those that haven’t heard of it, PBR is not natively supported on the 3560 - you must change the preferred SDM template to get this working.
*Mar 1 00:05:13.767: %PLATFORM_PBR-4-SDM_MISMATCH: PBR requires sdm template routing
DC_LAB_SWITCH(config)#sdm prefer routing
Changes to the running SDM preferences have been stored, but cannot take effect until the next reload.
Use 'show sdm prefer' to see what SDM preference is currently active.
This was a bit of informal (and long-winded) post, but I hope you followed along and that I saved you some pain with this stuff. Again, I encourage you to lab this up and watch the packet captures and logs to fully understand where your traffic is being sent, and how your devices are handling it.
For further understanding of how the ASA handles connections, or more specifically, packets that are or are not part of connections, read here