Title here
Summary here
April 15, 2013 in Systems6 minutes
Back to the basics today. I have seen this pop up a few times and wanted to offer some clarification on what seems to be a cloudy issue for CCNP (and some CCIE) candidates. I’ve seen quite a few times now where engineers see a route to Null0 in a Cisco router and assume instantly that the router is “black holing” traffic.

Sometimes, a route to Null0 is inserted into the routing table when performing summarization with nearly every routing protocol in common use today. Take this example topology, for instance:
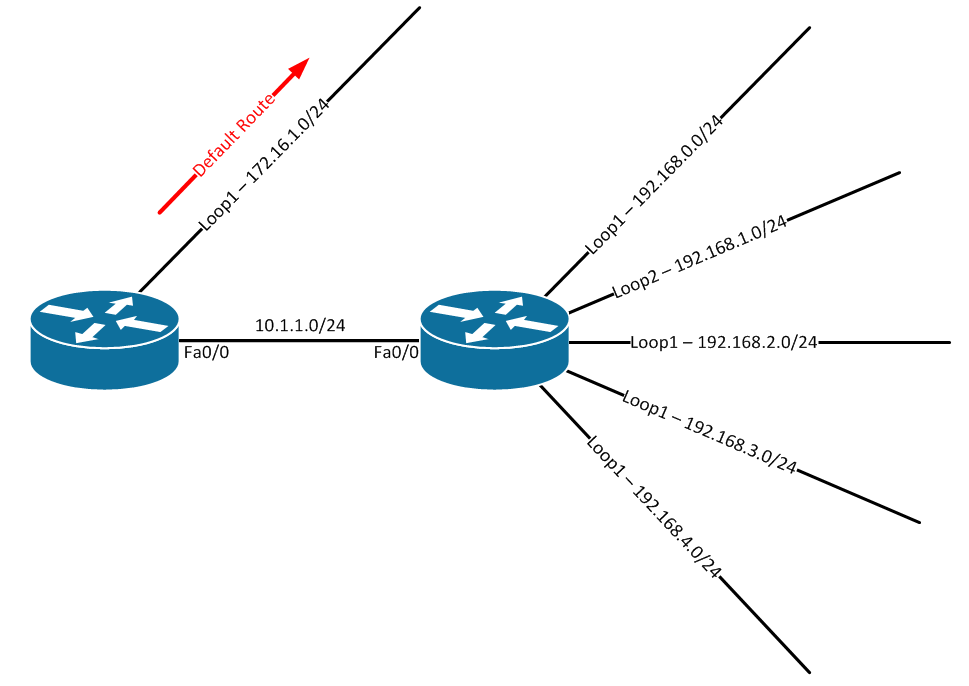
After initial configuration, the routing table on R1 looks like this:
R1#show ip route
[output omitted]
10.0.0.0/24 is subnetted, 1 subnets
C 10.1.1.0 is directly connected, FastEthernet0/0
D 192.168.0.0/24 [90/156160] via 10.1.1.2, 00:00:20, FastEthernet0/0
D 192.168.1.0/24 [90/156160] via 10.1.1.2, 00:00:15, FastEthernet0/0
D 192.168.2.0/24 [90/156160] via 10.1.1.2, 00:00:10, FastEthernet0/0
D 192.168.3.0/24 [90/156160] via 10.1.1.2, 00:00:07, FastEthernet0/0
D 192.168.4.0/24 [90/156160] via 10.1.1.2, 00:00:07, FastEthernet0/0
Let’s tidy this routing table up with a nice summary route from R2 that encapsulates these five routes. After all, they all have the same next hop, there’s really no need for the specificity.
R2(config)#int Fa0/0
R2(config-if)#ip summary-address eigrp 10 192.168.0.0 255.255.252.0
Of course, the world (even the theoretical one) isn’t perfect, so the best summary route we can do for this is a /21, which would encapsulate up through 192.168.7.0. We don’t have those networks assigned, and if this were a real world scenario, I’d go ahead and use a /22 and leave that extra network out of the summary, to avoid the problem we’re about to explore. However, for the sake of being exhaustive and learning more about this feature, let’s continue with this method.
Using this summary address, we see that our five networks have been nicely summarized down to
R1#show ip route eigrp
D 192.168.0.0/21 [90/156160] via 10.1.1.2, 00:02:49, FastEthernet0/0
And now for the moment when everyone (at least once) freaks out a little bit. Back on R2, we seem to have created a route to Null0.
R2#show ip route eigrp
D*EX 0.0.0.0/0 [170/28416] via 10.1.1.1, 00:06:11, FastEthernet0/0
D 192.168.0.0/21 is a summary, 00:04:37, Null0
But Null0 is the “bit bucket”!! That’s bad!
Well….Null0 is indeed the virtual interface on every Cisco router that is used to “black hole” traffic, for various reasons. Don’t worry though….this is no reason to fret. Take a look at R2’s full routing table:
R2#show ip route
[output omitted]
10.0.0.0/24 is subnetted, 1 subnets
C 10.1.1.0 is directly connected, FastEthernet0/0
C 192.168.0.0/24 is directly connected, Loopback1
C 192.168.1.0/24 is directly connected, Loopback2
C 192.168.2.0/24 is directly connected, Loopback3
C 192.168.3.0/24 is directly connected, Loopback4
C 192.168.4.0/24 is directly connected, Loopback5
D*EX 0.0.0.0/0 [170/28416] via 10.1.1.1, 02:41:29, FastEthernet0/0
D 192.168.0.0/21 is a summary, 02:39:55, Null0
You’ll notice that our summary route would also encapsulate the networks 192.168.5.0 - 192.168.7.0. Since these networks are not specifically present in the routing table, normal behavior would dictate that the default route (which is incidentally being advertised from R1) be used to get traffic out. So, for any of the networks that are part of the summary route but not locally represented, traffic would bounce back and forth between R1 and R2, causing a routing loop.
However, most routing protocols are aware that it’s quite common to have a summary route that doesn’t perfectly encapsulate the networks you intend to summarize. As a result, they inject a routing table entry with a length equivalent to the mask specified in the “ip summary-address” command, with a next-hop interface of Null0. Since legitimate traffic will choose the specific routes anyways (remember, the ****number one rule of routing is “the most specific route always wins”) the only traffic that this route will be used for is the potentially looping traffic destined for non-existent networks like 192.168.7.0/24 - networks that are part of the summary, but do not actually exist anywhere in the topology.
If you really want to remove this route - maybe to lessen confusion - you can advertise this summary address AND specify the Administrative Distance while doing so. An AD of 255 is a quick way to mark a route “dead”, so this action will remove the route from the table.
R2(config)#int Fa0/0
R2(config-if)#no ip summary-address eigrp 10 192.168.0.0 255.255.248.0 5
R2(config-if)#ip summary-address eigrp 10 192.168.0.0 255.255.248.0 255
Keep in mind, AD is not an attribute that can be transmitted through routing updates, so this merely affects the local interpretation of the summarization we’re performing, so the summary route will still be advertised to the EIGRP neighbors, who are by default programmed to accept this standard EIGRP route and install it with an AD of 90. So in effect, this will “remove” the route (more like make it ineligible) on R2, but R1 will still receive and use it. So…while it is removed on R2:
R2#show ip route eigrp
D*EX 0.0.0.0/0 [170/28416] via 10.1.1.1, 03:03:19, FastEthernet0/0
it is still present with the correct AD on R1, as it was before the change:
R1#show ip route eigrp
D 192.168.0.0/21 [90/156160] via 10.1.1.2, 00:02:09, FastEthernet0/0
However, we have essentially disabled the preventative routing measure that this feature had provided us. A ping to an address in the 192.168.7.0/24 network (which is inside the summary route but if you recall, does not exist on R2) will result in a routing loop.
R1#traceroute 192.168.7.1
Type escape sequence to abort.
Tracing the route to 192.168.7.1
1 10.1.1.2 36 msec 40 msec 16 msec
2 10.1.1.1 24 msec 16 msec 24 msec
3
*Mar 1 04:30:38.222: ICMP: time exceeded rcvd from 10.1.1.2
*Mar 1 04:30:38.266: ICMP: time exceeded rcvd from 10.1.1.2
*Mar 1 04:30:38.282: ICMP: time exceeded rcvd from 10.1.1.2
*Mar 1 04:30:38.302: ICMP: time exceeded (time to live) sent to 10.1.1.1 (dest was 192.168.7.1)
*Mar 1 04:30:38.306: ICMP: time exceeded rcvd from 10.1.1.1
*Mar 1 04:30:38.322: ICMP: time exceeded (time to live) sent to 10.1.1.1 (dest was 192.168.7.1)
*Mar 1 04:30:38.322: ICMP: time exceeded rcvd from 10.1.1.1
*Mar 1 04:30:38.342: ICMP: time exceeded (time to live) sent to 10.1.1.1 (dest was 192.168.7.1)
*Mar 1 04:30:38.342: ICMP: time exceeded rcvd from 10.1.1.1 * * *
In labbing this topology up, I was not immediately able to cause a routing loop, due to the fact that ICMP Redirects were enabled (they are by default in IOS - not sure if this has changed in later versions).
ICMP is able to send messages to neighboring devices when a packet arrives on the same interface that it would be leaving on. Obviously this would indicate some kind of inefficient routing, so R2 basically said to R1 - “You could do this more efficiently if you wanted, here, try the next-hop address that I’m using for that traffic.”
Since this next-hop was R1 itself, R1 viewed this as a bogus redirect:
R1#ping 192.168.7.1
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 192.168.7.1, timeout is 2 seconds:
*Mar 1 04:28:37.110: ICMP: bogus redirect from 10.1.1.2 - for 192.168.7.1 use gw 10.1.1.1
*Mar 1 04:28:37.110: gateway address is one of our addresses.
Easy enough to disable for the purposes of demonstrating the routing loop mentioned earlier:
R2(config)#int Fa0/0
R2(config-if)#no ip redirects
Read here for more on ICMP redirects on Cisco IOS:
http://www.cisco.com/en/US/tech/tk365/technologies_tech_note09186a0080094702.shtml