Title here
Summary here
May 21, 2013 in Systems8 minutes
There are a million articles out there on ESXi vSwitch Load Balancing, many of which correctly point out that the option for routing traffic based on IP Hash is probably the best option, if your upstream switch is running 802.3ad link aggregation to the ESXi hosts. It offers minimal complexity, while also providing the best load-balancing capabilities for network devices utilizing a vSwitch (Virtual Machine OR vmkernel). So…this article will be catered towards a very specific problem.
Since this post was inspired by an experience of mine, I will briefly explain the problem symptoms that surfaced as a result of incorrect settings that will be explored later in the post. A customer was having problems getting vSphere HA to converge properly, and was also having intermittent connectivity between vCenter and the ESXi hosts.
It was pretty bad - the vSphere client was laggy, vCenter’s resource utilization was pretty high, and I was getting strange messages like:
vSphere has detected that this host is in a different network partition that the master to which vcenter server is connected, or the Vsphere HA Agent on the host is alive and has management network connectivity but the management network has been partitioned. This state is reported by a vSphere HA master agent that is in a partition other than the one containing the host.
Duncan Epping has a great article on Host Isolation, specifically with regards to this error message as well.
It seemed like vCenter was able to get to the hosts, but the client kept refreshing like it was losing connectivity several times a second. I SSH’d into each of the hosts and discovered that they could not ping each other over the management network, and they definitely should have been able to.
The myriad of blog posts concerning vSphere Standard vSwitch redundancy typically will show a topology like this:
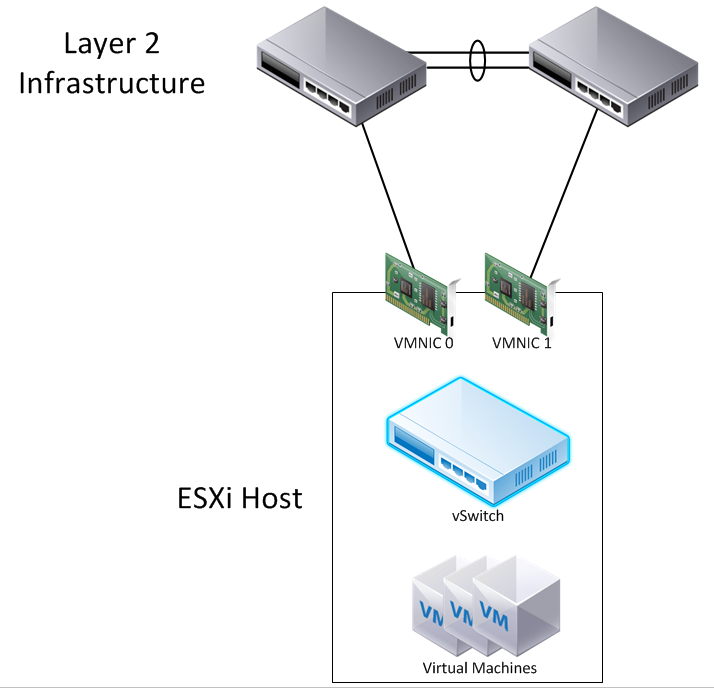
As mentioned before, you’ll have no trouble finding posts that explain the basics of how each vSwitch NIC Teaming policy works. If you prefer to hear it straight from the horse’s mouth, try VMware’s Virtual Networking Concepts whitepaper. If you prefer a more personal approach, this article by Ken Cline is very popular with respect to this topic.
I’ll assume you’ve at least read those two links by now, so as a quick summary, the available load-balancing policies on a vSwitch are:
Route based on the originating virtual port ID - this selects an uplink when a virtual device (virtual machine or vmkernel) attaches to the vSwitch. Traffic leaving this vNIC destined outside the host will always leave on that pre-determined pNIC, unless that pNIC were to fail.
Route based on IP Hash - this is nothing new to anyone familiar with 802.3ad; the idea is that a given packet has a hash made of it’s source and destination IP addresses, and the resulting math will determine which link is used to egress from the host. Traffic from the same IP address within the host to the same IP address outside the host will always leave on the same pNIC, but other traffic flows may fall on another NIC, even if the virtual source is the same.
Route based on source MAC hash - this is another hash-based selection mechanism, but since it’s only source based, and will correspond to an actual vNIC, this produces much the same behavior as the very first policy.
Use explicit failover order - not used very often. Suffice it to say it’s really not load balancing at all, it’s more of a hardcore deterministic method of placing traffic on the pNIC that you want. Should that pNIC fail, the next will be used.
Now, with respect to the problem I was experiencing in the first section; I had seen this behavior before, and knew that in the network topologies I’d worked with (etherchannel to the hosts in at least some way), the first policy where traffic is routed based on the originating virtual port ID would produce problems. To sum up that story, the customer was indeed using port channels from a Cisco 3750 stack, and after reading a fairly helpful KB article from VMware (ESXi Host Requirements for Link Aggregation), I had the documentation I needed to confirm with the customer that the appropriate policy for this topology was “route based on IP hash”.
Now - many of you know that my roots are not in virtualization, but on the network side, and I refused to leave it at that. That KB article did mention that IP hash method was required if the upstream switching fabric was running link aggregation.
Keep in mind that switch virtualization features like Cisco’s VSS or StackWise are included in this - those technologies are aimed at providing link aggregation without any specific host dependencies other than standardized 802.3ad
What that KB article failed to explain, however, is why this requirement was put into place. It’s clear that the first policy in our list does not work with link aggregation - the experience mentioned at the beginning made that very clear. What wasn’t clear was the technical reason for this. I wanted to know exactly why, when this policy is selected, pings between hosts management vmkernels did not succeed.
This deep-dive resulted in an exploration of exactly what’s happening within the vSwitch. When the “virtual port ID” policy is selected, each virtual NIC is more or less statically pinned to a given pNIC.
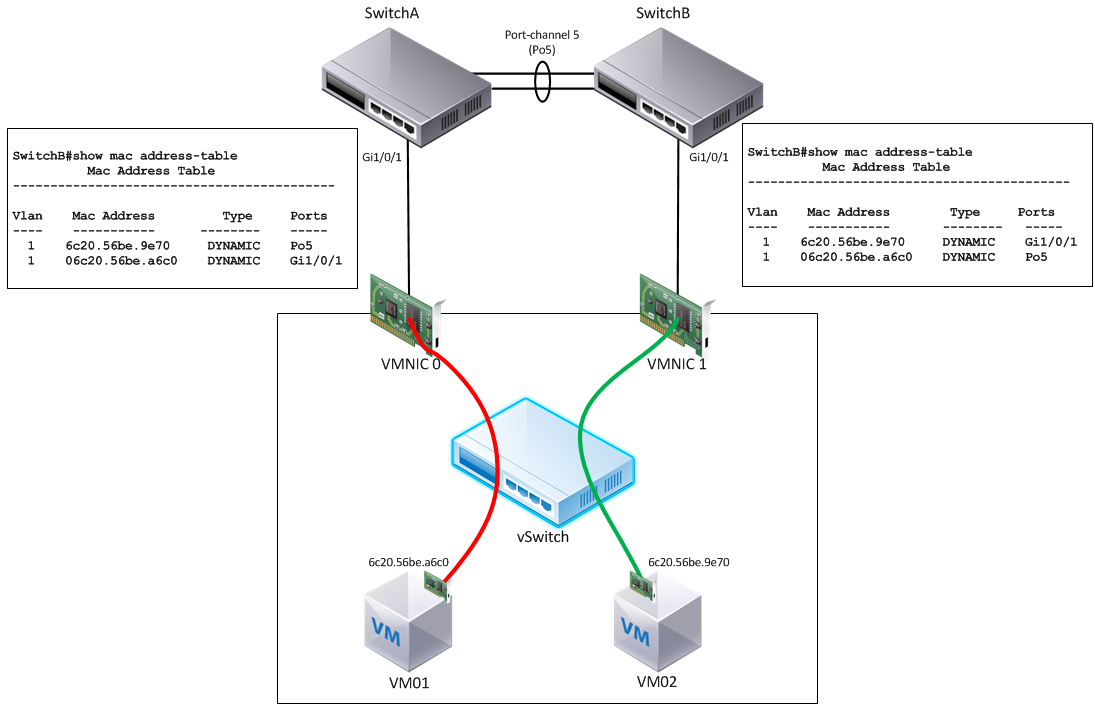
This allows us to have deterministic traffic flows, but just as important, it allows our upstream switching infrastructure to learn a given vNIC MAC address on a single physical switchport, rather than multiple.
Notice in the above diagram that no multi-chassis etherchannel is being attempted. The hosts are simply single homed to two completely separate upstream switches. Sure, those switches provide L2 connectivity for the whole thing using some kind of link between them, but that’s it. Any connection out of these hosts must go to one host or the other.
However, in today’s DC, this topology is becoming increasingly uncommon. Aside from the obvious single point of failure, this requires separate administration of each switch, and running link aggregation is a very common way to provide link redundancy. So, we want to use link aggregation, but how does this impact our virtual environment?
In smaller DCs, this is a fairly common topology:
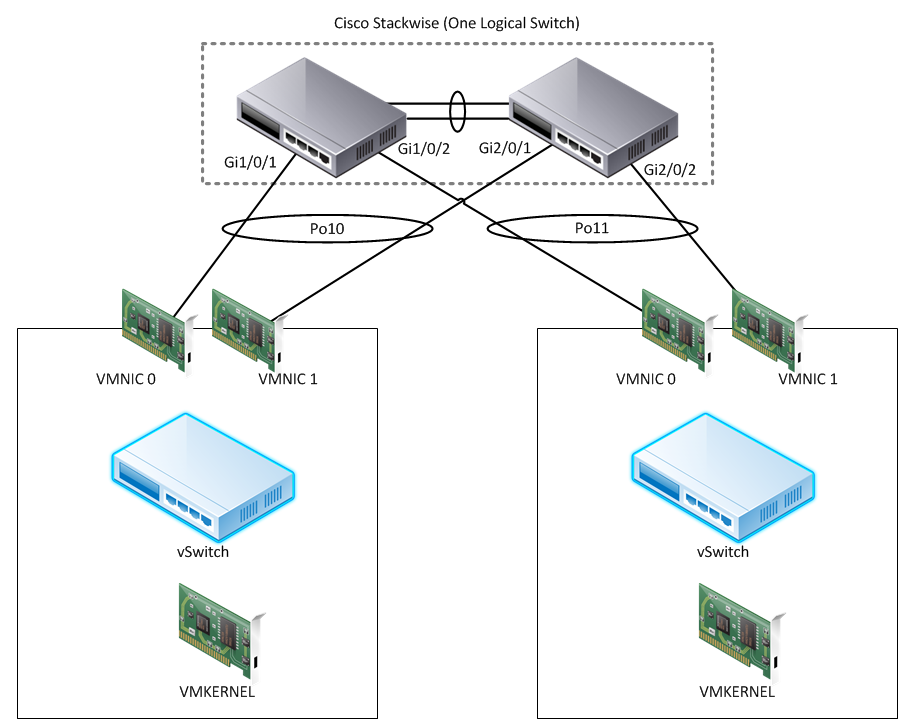
Don’t use Catalyst 3750s? The same applies with the 6500’s VSS feature. Same end-result, just a different method. vPC is a different beast, since vPC requires LACP to function properly and as mentioned, LACP is not supported on the standard vSwitch (it should be, though).
As you can see in the above diagram, we’re utilizing etherchannels between the switch stack (logically a single switch so that’s okay) and each ESXi Host. However, our load balancing policy is still set to the default of “route based on originating virtual port”. Remember, this policy pins traffic from a virtual port to a physical port, and traffic from that virtual port can ONLY ever leave the host on the port it was assigned.
Here’s where I stumbled across some additional vSwitch behavior that most resources on the web (actually all that I could find) fail to mention. Not only does this policy restrict the pNIC that a certain virtual entity can use to send traffic out of the host, but it also means that if traffic COMING IN to the host were to be received on another pNIC it is blocked by the vSwitch.
Maybe a visualization will help:
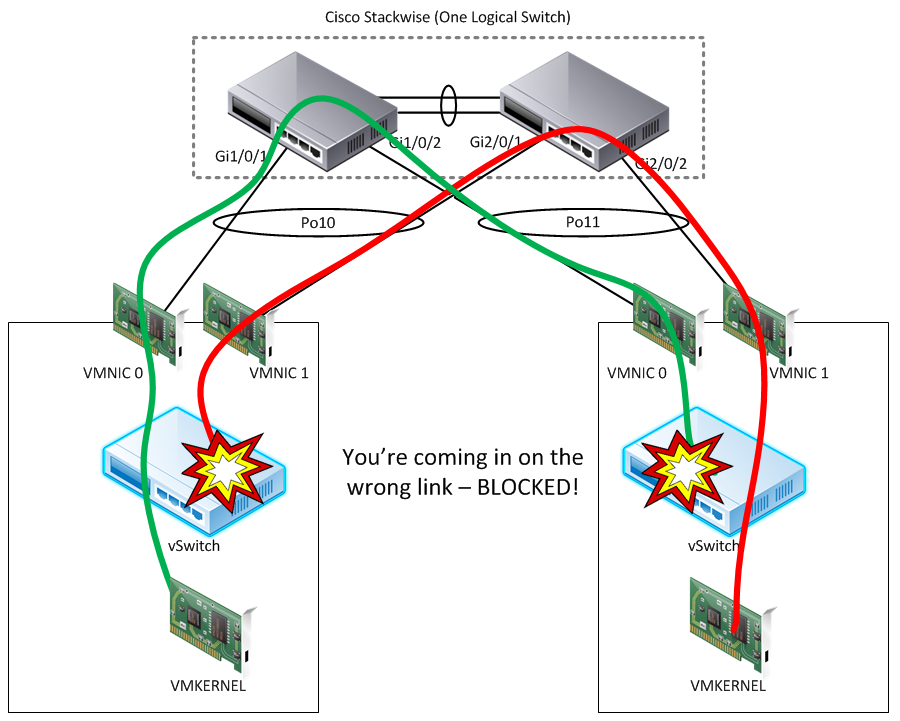
Note that on the left host, the traffic for the management vmkernel port is leaving on VMNIC0 (shown in green). This means that all traffic leaving that vmkernel destined somewhere outside the host will always leave on that NIC. However, the vmkernel for the other host is pinned to VMNIC1 (shown in red). Since other traffic destined for these vmkernels is being sent in to the host on a pNIC other than what it is pinned to, then that traffic is dropped. As I mentioned, most articles speak in depth about traffic leaving the host, but not about traffic being received by the host while in this mode.
The question remains - why is traffic entering what is clearly a non-working NIC for this traffic type? The answer lies in how 802.3ad works. Keep in mind that the recommendation is to NOT use this “virtual port ID” policy when 802.3ad is present, and this is why. Whenever you’re using this policy in vSphere, it’s aimed at allowing the switches to learn a given MAC on a single port, and none others. However, if the switches are configured for a port channel, MACs are not learned on physical interfaces, but on the logical port channel interfaces they’re a member of.
SwitchA#show mac address-table address 6c20.56be.a6c0
Mac Address Table
-------------------------------------------
Vlan Mac Address Type Ports
---- ----------- -------- -----
1 6c20.56be.a6c0 DYNAMIC Po10
When a frame enters the switch destined for the MAC address shown, the interface listed is a port channel interface. Because of this, the switch defers to whatever load balancing mechanism is configured on that switch - a common one is based off of source and destination IP address, just like the second vSwitch policy. Because of this, traffic heading towards the host may enter on a completely different link. The diagram shown above is more of a worst case scenario - it’s likely that certain traffic flows will work, and others will not. This was the case in my problem at the beginning of this post.
This is why you configure the second policy - “route based on IP hash”, rather than the default “virtual port ID” policy. The “ip hash” policy is the vSphere equivalent of standards-based 802.3ad. It knows the switch may send traffic on whatever link it chooses, so this policy allows such behavior.