Title here
Summary here
May 7, 2013 in Systems9 minutes
My post a few weeks ago about the CSR 1000v made a pretty big splash - it’s clear that the industry is giving a lot of attention to IP routing within a virtual environment. No doubt, Vyatta is largely credited for this, as they’ve been pushing this idea for a long time. When Brocade announced that they were acquiring Vyatta, and Cisco announced they were working on a “Cloud Services Router”, this idea became all the more legitimate, and as you can tell from this series, it’s of particular interest to me. The overwhelming majority of virtualized deployments in place today utilize L3 routing mechanisms that are outside the environment, usually physical routers or switches. This means the virtual environment is typically a collection of L2 broadcast domains, all of which connect via uplinks to aforementioned L3 devices. Not ideal, but widely accepted to be tolerable.
The concept of having a virtual entity capable of not only routing, but terminating VPN connections, performing basic security so that Secure Multi-Tenancy can be protected, all within the environment itself - is a pretty cool idea. However, how can we implement this technology while still properly protecting against downtime?
A few weeks ago, I posted about problems with First Hop Redundancy Protocols inside a virtual environment. There are a few important gotchas you should know about when considering FHRPs in your virtual environment, so I recommend reading that first.
We know that protocols like VRRP work well for first-hop redundancy and have for some time now. They’re a very tried-and-true way to provide basic L3 redundancy for devices that cannot talk routing protocols. However, in a virtualized environment we get other cool features like Fault Tolerance, which promises sub-second failover of VMs when the host they’re being run on fails. FT will have to be used in order to obtain immediate failover of the virtual machine itself in either case, but since the routers are also virtual machines, we have the option of sticking with something like VRRP, or configuring the router for fault tolerance as well. I’d like to go through both methods, and arrive at a conclusion where we know the pros and cons of each.
In the first post in this series, I described Cisco’s recommendation of one CSR per tenant. However, it would be nice to have two virtual routers like any campus network has, so that if one router dies (the whole host is a more likely event), the other router is able to take over. So, the recommendation would be to turn up two routers per tenant for reliability - and hey, let’s make the other router a Vyatta 6.5 image just to see these two kids play nice.
I threw together this topology to illustrate the parameters of the test:
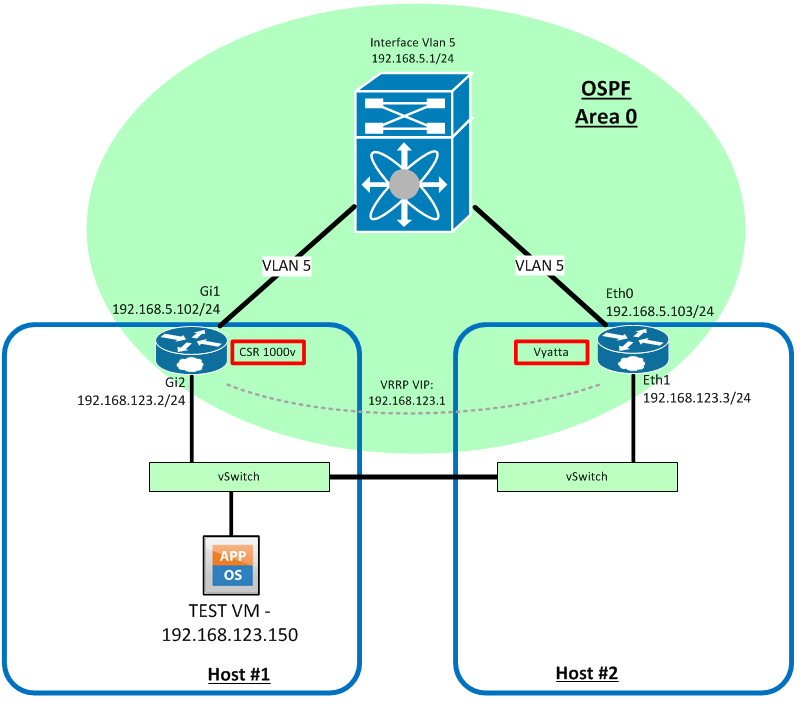
I did not configure the Vyatta or CSR for Fault Tolerance because with this method, I’m relying on VRRP to provide L3 failover capabilities. I did, however, configure it on the test virtual machine, as this would have to be done regardless, if maximum uptime was to be achieved. Otherwise we’d have to wait on HA to restart the VM on the working host, and it would miss the point of the test.
Be sure to configure anti-affinity rules in DRS (or similar feature) so that these two routers are never on the same host, which would defeat the purpose of redundancy, should that single host fail.
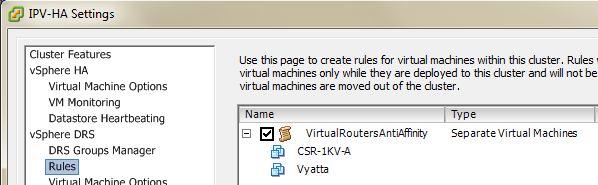
This configuration allows me to only configure the customer’s virtual machines for Fault Tolerance, rather than both the VM and the routers themselves. I will completely powercycle one of the hosts, and rely on proven protocols like VRRP to provide our default gateway failover. A constant ping to our test virtual machine reveals that:
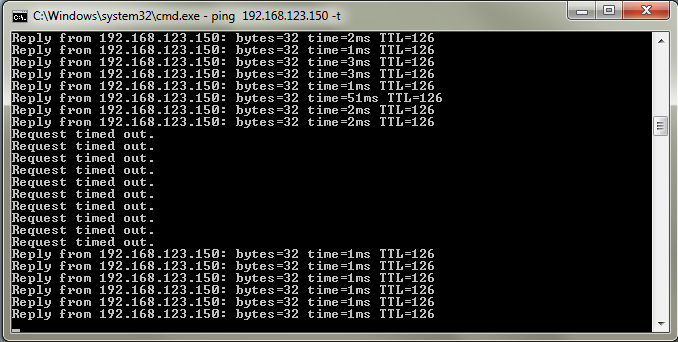
…we have incurred quite an unacceptable amount of downtime. This is about 40 seconds of downtime - hardly the speedy failure recovery we’re looking to accomplish.
So why the lengthy timeout period? VRRP shouldn’t be our problem - the backup router (Vyatta) should take over within a few seconds, as the default timers were used (master viewed as “dead” in about 3 seconds).
I was watching the logs of the “core” switch and noticed that the following log message appeared at nearly the exact same time that our virtual machine became reachable again after about 50 seconds of being unreachable:
*May 1 15:06:07: %OSPF-5-ADJCHG: Process 1, Nbr 192.168.123.2 on Vlan5 from FULL to DOWN, Neighbor Down: Dead timer expired
After analyzing the routing table during the time that this message appeared, I saw that the old route through the CSR was staying in the routing table until that neighbor’s dead timer expired. The CSR (and the host it was running on ) went down, but the core switch didn’t know that -after all, the core switch uses an SVI for establishing the OSPF relationship, as the physical connection to each host is a VLAN trunk. So, since the interface that OSPF is operating on (Vlan5) didn’t go down, the route through the CSR remained in the routing table until the neighbor went down. Since the default dead timer on an OSPF network type of BROADCAST is 40 seconds, this is going to have a pretty severe impact on our ability to fail over quickly.
I explained the concept of IGP Multipathing, and specifically how link-down events impact protocols like OSPF in a previous post. I suggest you read that to get a better idea of why the CSR was being used for all traffic flows, even though there were two L3 paths into the remote subnet.
The other question to consider is why the other route to the test virtual machine (through Vyatta) didn’t kick in right away - this was only used after the neighbor relationship with the CSR went down, even though both routes were equal-cost from the core switch perspective.
I had to make some changes on the Vyatta router to get the two routes to become equal-cost. The default behavior of the Vyatta router is to place a link cost of 10 on everything, which was much higher than the CSR1000v. Read this previous post for more on this and how to change it.
This method is not without it’s problems - OSPF is not normally used in exactly this way, so the failover speed isn’t quite up to where we were expecting. Read on to the end and I’ll summarize the problems and list a few ways you can use this method and not compromise as much on downtime.
This method won’t require a ton of explanation, just a quick identification of a pretty big caveat. Most are familiar with what Fault Tolerance does, and we’re using it on our test virtual machine regardless, so why not also use it for the router, rather than a FHRP like VRRP? The immediate benefit obviously being one less point of management per tenant, but perhaps you really really need one or two second failover, which FT is heralded as being able to provide.
First off, a big caveat - FT requires (among many other things) that virtual machines only have a single vCPU - any more than one means the VM is incompatible with Fault Tolerance.
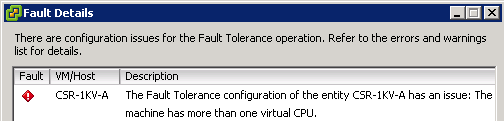
Cisco states in the CSR 1000v documentation that the required configuration is 4 cores on one CPU socket. These requirements immediately disqualify the CSR from being used with Fault Tolerance. Cisco being Cisco (no offense guys) I decided I wasn’t simply going to stop there, and I changed the default of 4 cores to one.
Vyatta does recommend multiple cores for heavy workloads or design requirements, but it is not required. Even a configuration capable of running a routing protocol, 4 interfaces, and up to 100Mbps works just fine with 1 vCPU.
So, the conclusion is already known - if you want to adhere to Cisco’s recommendations (and likely also continue to receive support for the product) you can’t use Fault Tolerance - bummer. Let’s do it anyways. Despite Cisco’s recommendations, the CSR worked well in my own test scenario with a single core. YMMV, of course.
I placed both VMs on our test host, after configuring both for FT.
I powercycled this host, and got GREAT results from a failover perspective.
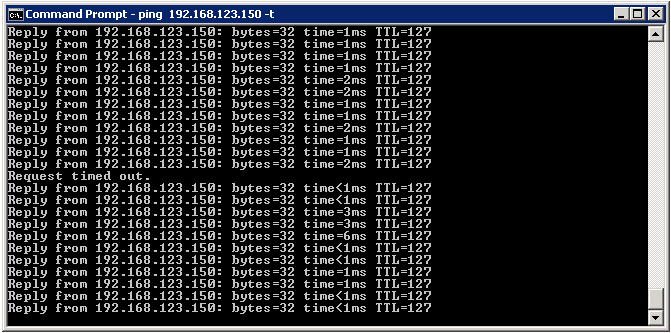
Remember that VRRP is not present in this method, and OSPF has no idea that the neighbor changed locations - it’s the same virtual machine, just on another switchport, so there is no need for OSPF failover to occur for any reason. The biggest hindrance to fast failover right now isn’t really much of one at all - it’s just the ability for the devices to send the requisite gratuitous ARPs so that the switching infrastructure learns that the MAC addresses corresponding to the known IPv4 forwarding addresses have moved. In some cases, we may not even drop a single ping (depending on timing). Regardless, this is impressive considering that we’re still routing inside the virtual environment, and we tested a potential worst-cast scenario, the death of an entire VM host. Not too bad.
However, as was mentioned before, using the CSR1000v for this purpose may not be appropriate, considering Cisco’s requirements. Cisco may change this in the future to reflect something like what Vyatta has laid out, but for now, if you really really want FT without breaking the rules, it may be better to use Vyatta, at least for the time being.
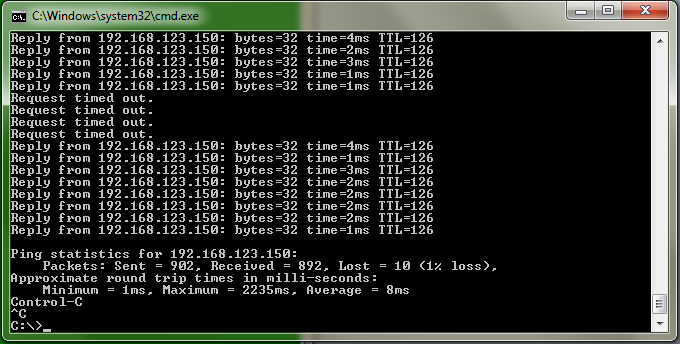
First off, the method utilizing VRRP can be made to work pretty well if you understand the timers OSPF puts into place by default. As mentioned before, the network type used here for OSPF will be BROADCAST, meaning a hello interval of 10 and a dead timer of 40. In this scenario, I was able to change this to a hello interval of 1 second and a dead interval of 3. This matches exactly the timers for VRRP, so both should reconverge at roughly the same time. The results I got were much better than without this change, but still not quite as good as Method 2:
That said, I’ve drawn up a quick “pros and cons” of sorts:

Use Method 1 if you have the CSR 1000v, at least for now. You may also use this if you’re a route/switch person and you’re used to working with routing protocols and VRRP/HSRP, etc. Method 2 might be better if you’re using Vyatta (or another platform with similar requirements) and/or if you’re more familiar with using FT for redundancy.
Networkworld has a pretty good (and recent) article talking about FT. Not specific to virtual routing, but the content is relevant regardless.