Title here
Summary here
November 6, 2013 in Systems11 minutes
In the last post, we discussed the hardware that was being announced from Cisco’s Insieme spin-in. While the hardware that is comprising the new Nexus 9000 series is certainly interesting, it wouldn’t mean nearly as much without some kind of integration on an application level.
Traditionally, Cisco networking has been relatively inaccessible to developers or even infrastructure folks looking to automate provisioning or configuration tasks. It looks like the release of ACI and the Nexus 9000 switch line is aiming to change that.
The Nexus 9000 family of switches will operate in one of two modes:
NXOS Mode - If you’ve worked with Cisco’s DC switches like the Nexus 7K or 5K, this should be very familiar to you. In this mode, you essentially have a 10GbE or 40GbE switch, with the features that are baked into that
In NXOS Mode, all of the additional custom ASICs that are present on the switch fabric are used primarily for enhancing the functionality of the merchant silicon platform, such as increasing buffer space, etc.
ACI Mode - This is a completely different mode of operation for the Nexus 9000 switch. In this mode, the switch participates in a leaf-spine based architecture that is purely driven by application policy. It is in this mode that we are able to define application relationships, and imprint them onto the fabric.
ACI is meant to provide that translation service between apps and the network. I was very happy to see this video posted on release day, as Joe does a great job at explaining the reasons for the product that he and the rest of the folks at Insieme have created:
This Nexus 9000 product family was built from the ground up, not just to be a cheap 10/40GbE platform, but also to be a custom fit for the idea of ACI. In this post, we’ll discuss this ACI engine (called the Application Policy Infrastructure Controller or APIC), as well as the direction that Cisco’s going from a perspective of programmability.
Before I get too deep into ACI, I do want to call out some of the programmability features present in the Nexus 9000 series even without ACI (since NXOS mode is all we’ll be able to play with initially). The fact that the list below is so long, even in a mode that really only requires you to purchase the hardware and little else, is impressive, and certainly a refreshing turn for the better from a Cisco perspective.
The folks over at Insieme have gone through some great lengths to enable the Nexus 9000 switches with some great programmable interfaces, which is a huge move forward for the Nexus family, and with Cisco products in general, frankly. Here are some of the ways you’ll be able to interact with a Nexus 9000 switch even in the absence of ACI:
This is a stark contrast to what we were given in the past. We’ve been able to do really cool stuff with interfaces like these on competing platforms like Juniper and Arista, but not with a Cisco switch. So - this is very good news. Again, these interfaces do not require ACI - though obviously ACI is needed if you want to administer an entire fabric of switches as one.
By the way, the long-term vision is to move all of these features into every NXOS device, which is very good news for those that recently bought a lot of existing Nexus 5000/7000 gear, for instance.
@Bigmstone yes, they will be rolled into all nexus products over time.
— Joe Onisick (@jonisick) November 6, 2013ACI is all about policy-based fabric automation. When we’re talking about network agility, and creating an environment where the application and developer teams are able to consume network services without having to understand how the network works, this policy abstraction is crucial.
ACI extends the same concept we saw with UCS Service Profiles by using Application Network Profiles. These contain network-related attributes about an application. They can define things like:
When you’re working with a fabric composed of Nexus 9000 hardware, ACI becomes the layer that sits on top and enables network orchestration, and integration with other tools like OpenStack, etc.
Application policies will be configured in terms that make sense to application folks, abstracting away all of the network-specific nerd knobs for those with that skillset. The main focus is to remove the complexity out of the network to allow for true network automation.
It should be noted that there is still a need for traditional network engineers to understand the fabric design underneath, which we’ll get into in a bit.
The main task is to define your application profiles to essentially describe their respective application’s impact on the network. Once done, policies can be configured by the same application folks to define relationships between these profiles.
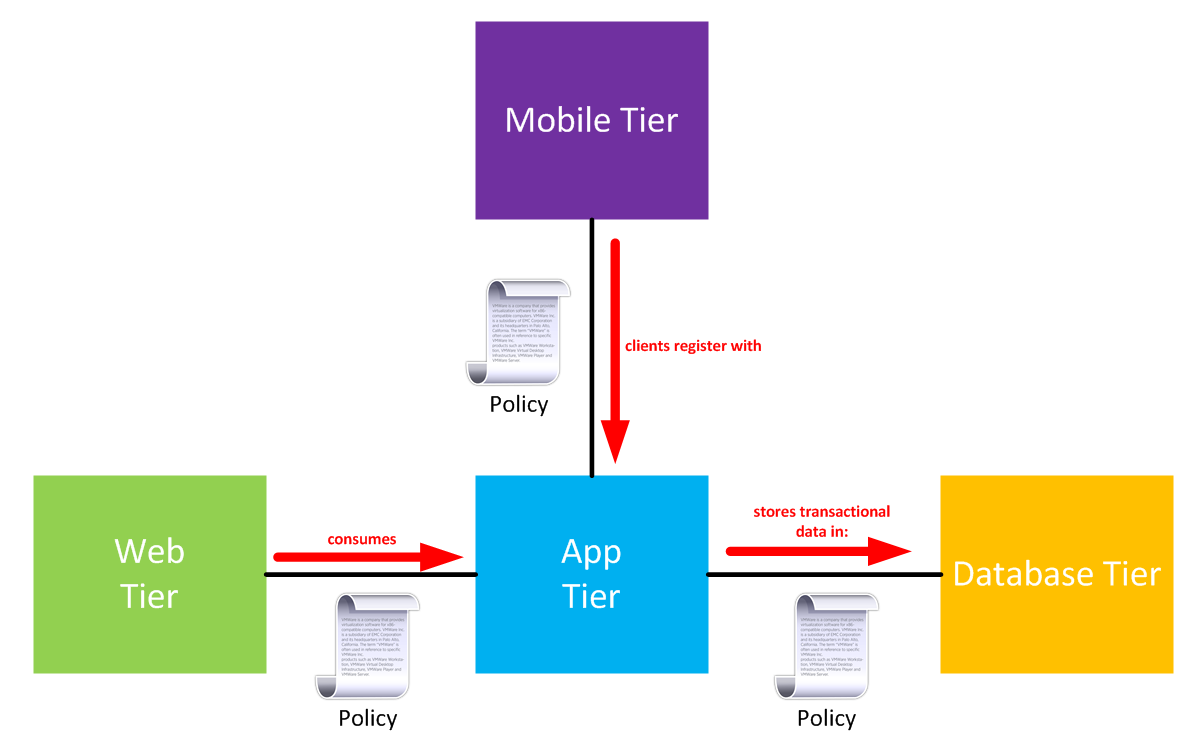
Note that zero networking knowledge is needed for this. As an application developer or owner, you’re configuring relationships using verbs like “consume” or “register” or “store”. Those are the words you’re used to using. That’s the idea here - abstract the networking nerd knobs away and let the network engineers maintain them.
All of this is possible through the Application Policy Infrastructure Controller, or APIC. This is the policy server for ACI. In order to create an ACI fabric, you connect the APIC into a leaf switch. As soon as you plug this in, it discovers the entire topology in an automated fashion. The APIC is responsible for taking created policies and imprinting them onto the network.
ACI is being positioned to act as a translator between the application teams and network teams. It allows for a plug and play semantic of network elements allowing policy groups to pick and choose from a menu list of network structures that they want to utilize (QoS, FW, etc.). This is nothing new for Vmware admins who have worked with port groups on a vSwitch or anyone familiar with vNIC or vHBA templates in Cisco UCS - except that with solutions like Cisco ACI or Vmware NSX, the connectivity options offered behind the scenes is much more rich.
These attributes can be tied to network connectivity policies so that they’re abstracted from the application teams, who end up selecting these policies from a dropdown or similar.
Now - for all of you network folks, let’s talk about how this fabric works behind the scenes.
The typical ACI fabric will be designed in a traditional leaf-spine architecture, with 9500s serving as the spine, and 9300s serving as the leaf switches.
The workloads and policy services connect directly into the leaf switches of the fabric. This can be baremetal workloads, or hypervisors.
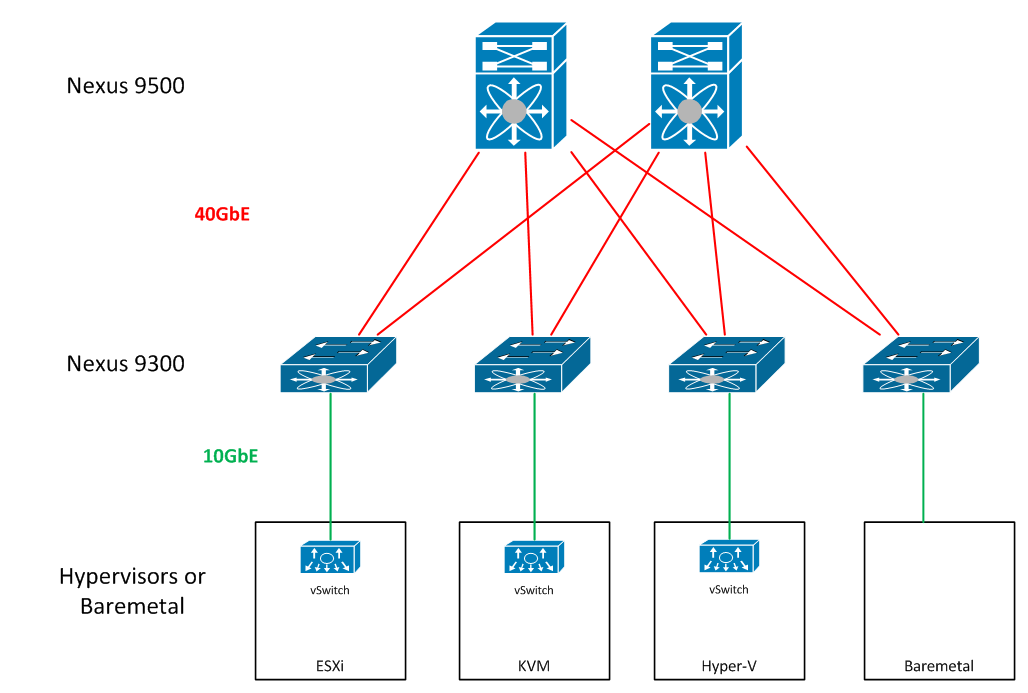
An ACI fabric operates as a L3 routed leaf-spine fabric with VXLAN overlay. There is no TRILL or FabricPath anywhere - so redundancy is accomplished via L3 ECMP.
There are a few attributes that will be used from day 1 to offer application identification:
Each ingress port on the fabric is it’s own classification domain - so using the traditional VLAN model may not be a bad idea - since VLAN 10 on port 1 means something completely different than VLAN 10 on port 2. However - all IP gateways can also be made available across the fabric on any leaf. This means a lot when it comes to workload mobility.
Routing integration can also take place between the ACI fabric and an edge router using iBGP, OSPF, or static routing.
Every port on the 9000 fabric is a native hardware VXLAN, NVGRE, and IP gateway. As you can imagine, this means that our flexibility in tagging mechanisms outside the fabric is a lot better. We can really just use whatever we want, and coordinate the tags that are being used using policy. The fabric will rewrite as necessary - allowing a Hyper-V host and an ESXi host to talk using both of their native tagging mechanisms at line rate.
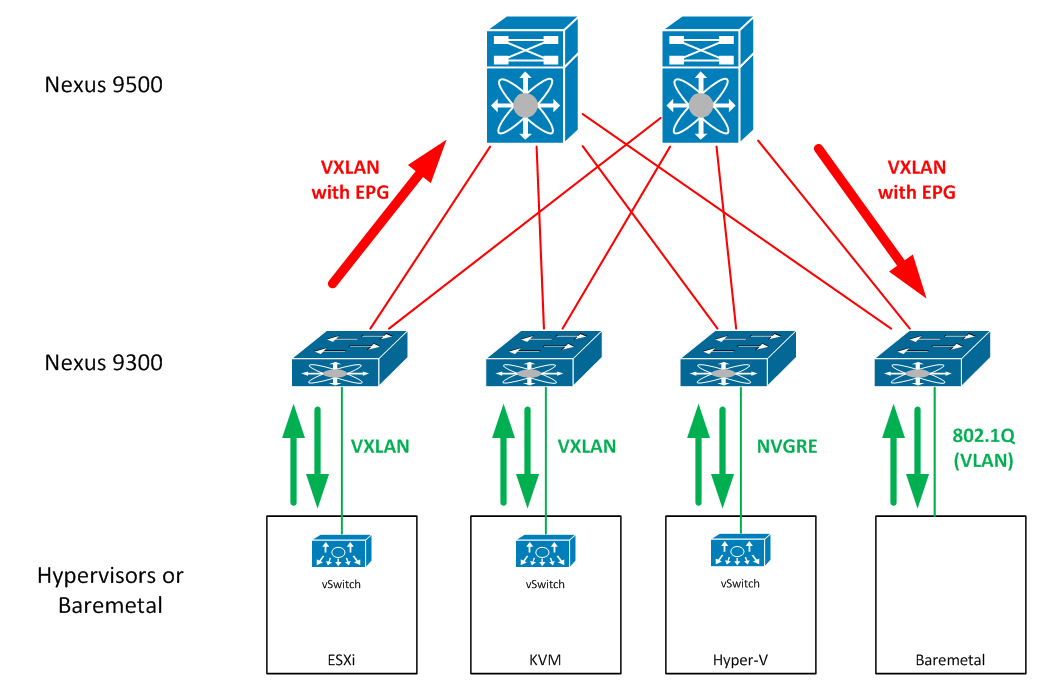
Because classification occurs at the edge, each leaf essentially serves as a gateway for any tagging mechanism. This function is able to translate between VXLAN, VLAN, NVGRE, etc. - all at line rate in hardware. This also means that integration of these application policies between virtual and physical workloads is seamless.
This obviously requires some overall orchestration between the hypervisor and the fabric, because there’s only a small number of attributes usable for this classification. You’d have to reach into the API of - say vSphere - and figure out what tags are being used for what virtual machines, then make sure you use those tags appropriately as they enter the fabric. Eventually, other attributes could include:
These, as well as others, could all potentially be used for further granularity when identifying application endpoints. Time will tell which ones become most urgent and which ones Cisco adopts. Personally, I’ve had a ton of ideas regarding this classification and will be following up with a post.
In normal networks, any time you’re talking about multiple paths, whether it’s a L3 ECMP with Cisco IP CEF or similar, or simple port channels, it’s typically per-flow load balancing, not per-packet. So as long as traffic is going to the same IP address from the same IP address, that traffic is only going to utilize a single link, no matter how many are in the “bundle”.
This is to limit the likelihood of packets being delivered in the wrong order. While TCP was built to handle this event, it is still stressful on the receiving end to dedicate CPU cycles to put packets back in the right order before being delivered to the application. So - by making sure traffic in a single flow always goes over a single link, it forces the packets to stay in order.
The ALE ASIC is able to do something extremely nifty to help get around this. It uses timers and short “hello” messages to determine the exact latency of each link in the fabric.
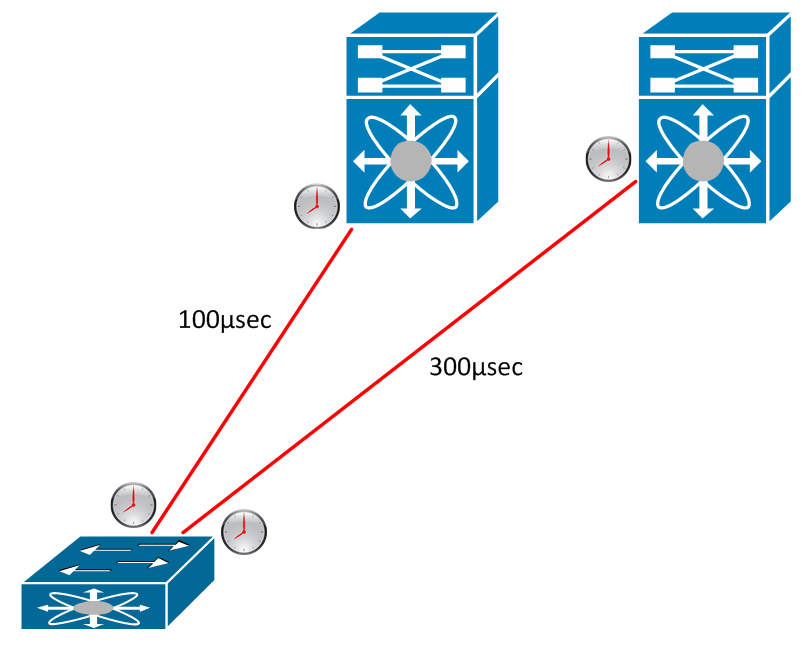
This is HUGE because it means that you know the exact latency for each link all the time. This allows you to do true link balancing, because you don’t have to do tricks to get packets to arrive in the right order - you simply time it so that they do. As a result, our entire fabric can use each link to it’s full potential.
This is a big argument for using a hardware solution because the fabric can make the best decisions about where to place the traffic without affecting, or requiring input from the overlay.
An ACI fabric can operate in a whitelist model (default) or a blacklist model. Since the idea is to enable things from an application perspective, then in order to get connectivity you must first set up application profiles and create the policies that allow them to talk. Or, you could change to a blacklist model, denying the traffic you don’t want to exist.
There are a handful of benefits here - first off, ACLs aren’t really needed and wouldn’t be configured on a per-switch basis. This “firewall-esque” functionality simply extends across the entire fabric. Second, it helps prevent the issue of old firewall rules sticking around long after they become irrelevant.
So, a security configuration is always up to date and allowing only the traffic through that needs to get through because these are configured in application profiles, not in an ACL that’s only updated when things aren’t working.
Application Profiler is a custom tool built by Cisco to sweep the network to find applications and their configurations so that a Fabric network can be planned accordingly.
Simulators will be available along with the full API documentation but not necessarily a script library, such as what is provided for UCS (PowerTool/PowerShell). This could be developed on day one using the XML/JSON API being provided.
The list of mechanisms by which we’ll be able to programmatically interact with ACI is quite extensive (a good thing):
Disclaimer - This article was written based off of informal notes gathered over the course of time. This article is merely intended to serve as an introduction to the concept of Nexus 9000 and ACI, and as such is potentially subject to factual errors that I may go back and make corrections to. I was not asked to write this article, but I did seek out factual details on my own because I wanted them for the purposes of accuracy. I also attended the Cisco ACI launch event as a Tech Field Day delegate. Attending events like these mean that the vendor may pay for a certain portion of my travel arrangements, but any opinions given are my own and are not influenced in any way. (Full disclaimer here)