Title here
Summary here
December 16, 2013 in Systems4 minutes
I was troubleshooting an MTU related issue for NFS connectivity in a Flexpod (Cisco UCS, Cisco Nexus, and Netapp storage with VMware vSphere, running the Nexus 1000v). Regular-sized frames were making it through, but not jumbo frames. I ensured the endpoints were set up correctly, then moved inwards….in my experience, the problem is usually there.
The original design basically included the use of CoS tag 2 for all NFS traffic, so that it could be honored throughout the network, and given jumbo frames treatment.
This was easy enough to do with a Nexus 1000v port profile for all vSphere VMKernel interfaces:
1KVVSM# show run port-profile NFS
port-profile type vethernet NFS
vmware port-group
switchport mode access
switchport access vlan 260
service-policy input TAG_COS_2
no shutdown
max-ports 96
state enabled
I looked on the 1000v uplink port profile, I looked everywhere in UCS, and the Neuxus 5Ks. I had this CoS tag going to the “Silver” class in UCS and the Nexus 5K pair:
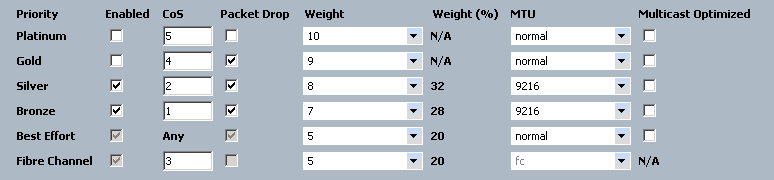
I was at a loss. Then I realized that I hadn’t done anything to classify the traffic coming from the storage array, which was also directly connected to the Nexus 5Ks. So just to get things working, I went ahead and just enabled jumbo frames on the default class (unclassified traffic). I’d have to figure out how to classify that traffic later - probably with a per-port policy-map. (ick)
However, jumbo frames still weren’t working! I enabled jumbo frames on the default class, or as I like to call it, the “screw-it-we’ll-deal-with-it-later” class.
Now I was really frustrated. So, I got out one of my favorite MTU troubleshooting commands, which is:
show queuing interface
and after verifying that all of my QoS groups that I expected to have jumbo frames had the correct MTU set, and they did.
That’s when I noticed something peculiar. Under QoS group 4, which I had not intentionally done anything with in my configuration, I noticed some packets were coming in.
DCB5596LANA# show queuing int Eth1/35
(some output omitted)
RX Queuing
qos-group 4
q-size: 22720, HW MTU: 1500 (1500 configured)
drop-type: drop, xon: 0, xoff: 22720
Statistics:
Pkts received over the port : 1651
Ucast pkts sent to the cross-bar : 1651
Mcast pkts sent to the cross-bar : 0
Ucast pkts received from the cross-bar : 0
Pkts sent to the port : 0
Pkts discarded on ingress : 0
Per-priority-pause status : Rx (Inactive), Tx (Inactive)
Obviously this isn’t always the case, but it just so happens that anything with a CoS tag of 4 makes it into this QoS group. That’s how I have my policy maps configured:
class-map type qos match-all class-gold
match cos 4
class-map type qos match-all class-bronze
match cos 1
class-map type qos match-all class-silver
match cos 2
class-map type qos match-all class-platinum
match cos 5
policy-map type qos system-level-qos
class class-platinum
set qos-group 5
class class-gold
set qos-group 4
class class-silver
set qos-group 3
class class-bronze
set qos-group 2
class class-fcoe
set qos-group 1
This means that the traffic leaving the Netapp filers (non-FCoE anyways) is automatically marked with a CoS value of 4. This is good news for me, because I ultimately don’t really care what CoS values are used, as long as it’s something. Any value will allow me to place that traffic into a class other than the default class, which is one of my own personal recommendations for this kind of configuration. No way to shoot yourself in the foot later that way.
The fix was simply to use this to my advantage. Rather than use a CoS tag of 2, which was more or less arbitrary, I just moved the NFS class to use CoS 4. It would be nice in the future if Netapp allows this value to be configurable, but until then I can make this work.
So there you have it. If you’re using a Netapp filer for IP storage, make use of the fact that these markings are taking place.