Title here
Summary here
January 19, 2014 in Systems5 minutes
When upgrading UCS firmware, it’s important to periodically check the state of the HA clustering service running between the two Fabric Interconnects. The infrastructure portions of UCS are generally redundant due to these two FIs but only if the clustering service has converged - so it’s important to use the “show cluster state” command to verify this is the case. During a firmware upgrade to 2.2(1b), I checked this:
6296FAB-A# connect local-mgmt
6296FAB-A(local-mgmt)# show cluster state
Cluster Id: 8048cd6e-5d54-11e3-b36c-002a6a499d04
Unable to communicate with UCSM controller
The error message - “unable to communicate with UCSM controller” worried me, and it was given when I ran the “show cluster state” command as well as the “cluster lead” command - the latter of which is necessary to switch an FI’s role in the cluster from subordinate to primary. Seeing as I couldn’t do either of these things because of this error, I felt like I was in a bind, unable to verify the state of HA.
First of all, I’d like to point out that this info is also available in the UCSM GUI. I took a look there and noticed that it was reporting HA was fully converged and ready:
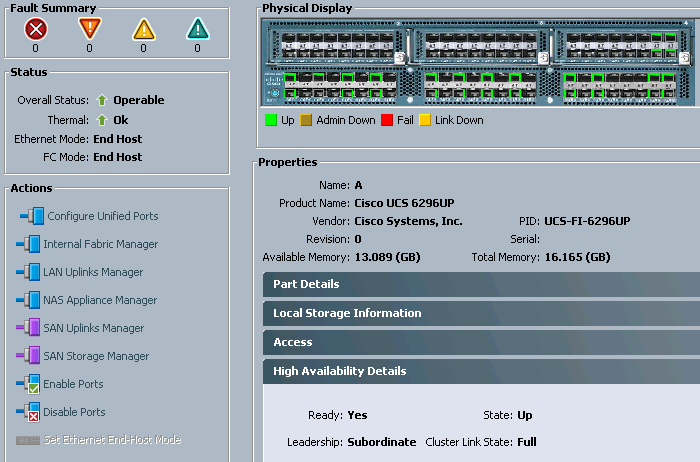
As we’ll see shortly, this can actually be a preferred way of verifying the HA cluster state. For now, suffice it to say that this was a valid indicator of the state of HA, and the “unable to communicate with UCSM controller” error I was seeing was purely cosmetic.
The TAC engineer I was working with was kind enough to load the revered UCS debug plug (available only internally to Cisco TAC and is generally not used unless something is seriously messed up) into my UCS domain and show me a “backdoor” command that accesses UCSM directly to verify the HA state.
6296FAB-A(local-mgmt)# load-debug-plugin volatile:x
###############################################################
Warning: debug-plugin is for engineering internal use only!
For security reason, plugin image has been deleted.
###############################################################
Successfully loaded debug-plugin!!!
Linux(debug)# /isan/bin/svc_sam_controller --c /opt/db/sam.config extstate
Cluster Id: 0x8048cd6e5d5411e3-0xb36c002a6a499d04
Start time: Sat Jan 18 04:38:39 2014
Last election time: Sat Jan 18 05:27:38 2014
A: UP, SUBORDINATE
B: UP, PRIMARY
A: memb state UP, lead state SUBORDINATE, mgmt services state: UP
B: memb state UP, lead state PRIMARY, mgmt services state: UP
heartbeat state PRIMARY_OK
INTERNAL NETWORK INTERFACES:
eth1, UP
eth2, UP
HA READY
Detailed state of the device selected for HA storage:
Chassis 2, serial: FOX********, state: active
Chassis 3, serial: FOX********, state: active
Chassis 4, serial: FOX********, state: active
The reason I was seeing the error outside of the context of this debug plugin is actually a little disturbing, and is one of several reasons why I’m super uncomfortable with UCSM release 2.2(1b) in general (some I’ve already wrote about, some I have yet to).
The TAC engineer I was working with mentioned that the UCSM XML API, which is used by both the UCSM Java GUI as well as any third party tools (i.e. UCS PowerShell module aka PowerTool) offers direct access to UCSM itself. The “show cluster state” and “cluster lead” commands available from the CLI of the Fabric Interconnects is apparently powered by a “middle man” binary on the filesystem that works as a proxy between the clustering services in UCSM and the command line interface on the FIs.
This binary, as of firmware 2.2(1b), is called “pidof”, found in the /bin directory (which is viewable only with this internal only debug plugin, to my knowledge).
Linux(debug)# cd /sbin/
Linux(debug)# ls
agetty haltkillall5 plipconfig sfdisk
badblocks hwclockklogd pmap_dump shutdown
blockdev ifconfigldconfig pmap_set slattach
bootlogd ifdownlosetup portmap sln
cfdisk ifuplsmod poweroff start-stop-daemon
dumpe2fs initlspci rarp sucap
e2fsck insmodmkcramfs reboot sulogin
execcap ipmke2fs resize2fs swapoff
fdisk ip6tablesmkfs rmmod swapon
fsck ip6tables-restoremkfs.cramfs route sysctl
fsck.cramfs ip6tables-savemkfs.ext2 rtacct tc
fsck.minix iptablesmkfs.minix rtmon telinit
fsck.nfs iptables-restoremkfs.vfat runlevel tune2fs
getpcaps iptables-savepcimodules setpcaps unix_chkpwd
getty kexecpivot_root setpci
Linux(debug)# cd /bin/
Linux(debug)# ls
arch ddgrep mktemp readlink tar
awk deletegunzip more red tcsh
bash dfgzip mount rm tempfile
busybox dirhostname move rmdir touch
cat dmesginclude mv run-parts true
chgrp dnsdomainnameip netstat sed umount
chmod domainnamekill nice sh uname
chown echoln nisdomainname showfile uncompress
chroot edloadkeys pidof sleep usleep
copy egreplogin ping stat vdir
cp falsels ping6 stty vi
cut fgrepmkdir ps su ypdomainname
date fusermknod pwd sync zcat
Turns out that prior to this version of UCSM (2.2(1b)), this binary was in the /sbin directory, so in this release it was moved. Unfortunately, the symlinks present on the fabric interconnects still point to the old location until upgraded - so if you follow the upgrade docs (you should) then you’ll get this error after activating UCSM but before you activate the Fabric Interconnects. This is kind of a pain in the ass because you can’t verify the cluster state using the CLI until you activate the FIs. Sure, you should look at the UCSM GUI as I showed you before, but during an upgrade of a system running 10+ chassis that is FULLY in production, these kind of errors still shake you up a little bit.
So the moral of the story is that this kind of error should have been caught in QA and customers/partners should have been advised of it in the release notes. It may be cosmetic in nature but as I said, that excuse usually doesn’t cut it when an entire production data center is on the line.
As usual, follow the docs to the letter, and if you see errors like this, call TAC. It appears that I may be getting some traction with these errors I’ve been having with this release and will hopefully help drive a new release of UCSM - every issue I run into convinces me further that these newer versions need better/more Quality Assurance before release.