Title here
Summary here
January 20, 2014 in Systems4 minutes
Sadly, this will be another post regarding issues I’ve had with UCSM firmware release 2.2(1b). During the upgrade process, I experienced a lot of issues with data plane connectivity - after I activated (and subsequently rebooted) a Fabric Interconnect, and it came up with the new NXOS version, a slew of blades would have persistent errors regarding virtual interfaces (VIFs) that wouldn’t come back online.
Here is the error report for a single blade where I was seeing these errors:
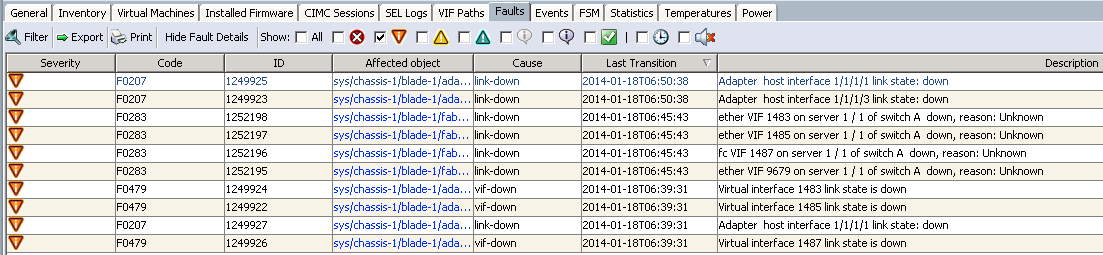
The ones I was most worried about were those that said “ether/fc VIF [id] on server [server] of switch [switchid] down, reason: Unknown”. Pretty much any time I see a reason of “unknown”, an eyebrow gets raised.
Note that these errors are all bound to the A-side Fabric Interconnect. This was because I had just activated and rebooted this fabric interconnect as part of a firmware upgrade to 2.2(1b)
Now - errors regarding VIFs being offline or disconnect are normal after a firmware upgrade of a Fabric Interconnect immediately after it comes back online after a reboot, but these errors persisted after more than sufficient time, and ESXi was still reporting that the NICs and HBAs pinned to that fabric were disconnected. Essentially, from the host’s perspective, that fabric may as well have not come back online at all, since there was no functioning connectivity to it, storage or data. Any vHBA or vNIC pinned to the Fabric Interconnect that just completed the upgrade was simply not connected.
It wasn’t just this server, either - oh no. It appears that this impacted quite a few servers. I made this upgrade quite a few times (I was working with multiple UCS domains), and although the number of servers affected has been different every time I’ve made the upgrade, the fact that it happens at all is consistently true.
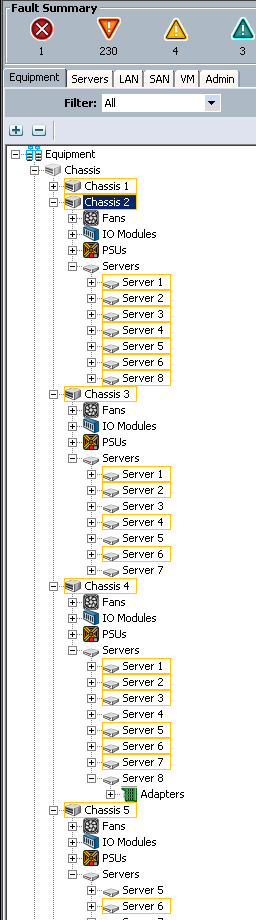
Each server highlighted in orange was suffering from this issue - they were literally and completely disconnected from the Fabric Interconnect that had just been upgraded to 2.2(1b). Because of this consistency, I am fortunately getting some additional attention from TAC and they’re looking into this more deeply, with the intention of getting it identified as a defect, potentially resulting in a new UCSM release.
UPDATE: The sad result from this TAC case was that they were not able to reproduce the scenario in their lab. Sorry, I was also hoping for a better answer as well.
So how do we fix this? (This is the part that really sucks) Unfortunately, the only way to resolve these errors is to perform a rediscovery of each and every blade with the issue. The process for doing this is as follows:
Shutdown and disassociate the service profile for the affected blade. Obviously this means the blade will need to go offline during this period.
Once the blade has been fully disassociated (look for “disassociated” in the blade status box), decommission it.
This will generate a prompt to re-discover the blade. Do this, and wait for the blade status to return to “Unassociated” - this will take a while.
Re-associate the service profile to the blade and it should boot normally, and the errors we saw before should not re-appear.
This process should allow the blade to come up normally, with all VIFs active and forwarding. Check the “VIF Paths” tab to verify this.
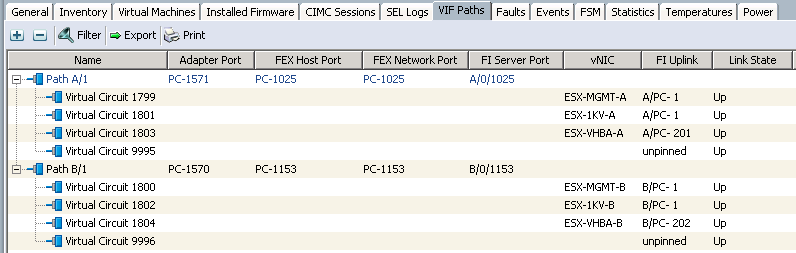
Unfortunately….this really sucks if there are a large number of blades with this issue (like I did), since you’ll have to repeat this process for every affected blade. While it’s true that when running workloads like vSphere, you can easily place these hosts into maintenance mode while running this task, it’s still a massive inconvenience, and takes up huge chunks of time during an otherwise brief maintenance window.
I recommend you stay tuned to my blog, as I’ll be releasing a post very soon that goes into detail regarding the verification of data plane connectivity in Cisco UCS. Armed with knowledge and tools explained in that post, you can achieve a better understanding of network and storage connectivity within UCS, and avoid any data plane disruptions, whether caused by a firmware issue or otherwise.