Title here
Summary here
March 11, 2014 in Systems5 minutes
When using overlays, its important to remember (in most cases) that an entire Ethernet frame is being encapsulated in something else (usually Ethernet + IP + UDP + Overlay Header). This means that the Maximum Transmission Unit for the underlay must be adjusted.
There are a number of posts out there about correct MTU settings for VXLAN. Unfortunately, many of them are either wrong, or unclear as to the math behind these calculations. I will attempt to clarify my findings, and if I am in error, please don’t hesitate to comment and I’ll fix.
It’s important to remember that Ethernet MTU (standard of 1500 bytes) accounts only for Ethernet’s payload, excluding the Ethernet header itself. This means that the outer header length of 14 bytes, as well as the addition of 4 bytes for an outer VLAN, is unnecessary. It may also become a common practice to run VXLAN over a purely routed IP fabric, in which case VLANs would not be used anyway.
It’s also worth noting the original Ethernet preamble or trailer is not part of any of these calculations. The inner Ethernet frame excludes these, as they are unnecessary. The “outer frame” has it’s own preamble and trailer, offloaded as usual by the host NIC - also not part of any MTU calculations.
Many vendor docs state that an extra 50 bytes is needed for overhead. This assumes a VLAN tag is not being used on the inner payload.
The VTEP interfaces themselves must perform a re-calculation of the inner frame’s FCS upon decapsulation, as this information is not carried in the VXLAN payload (and why would it be - the outer frame has it’s own FCS, and the inner frame would be included in its calculation).
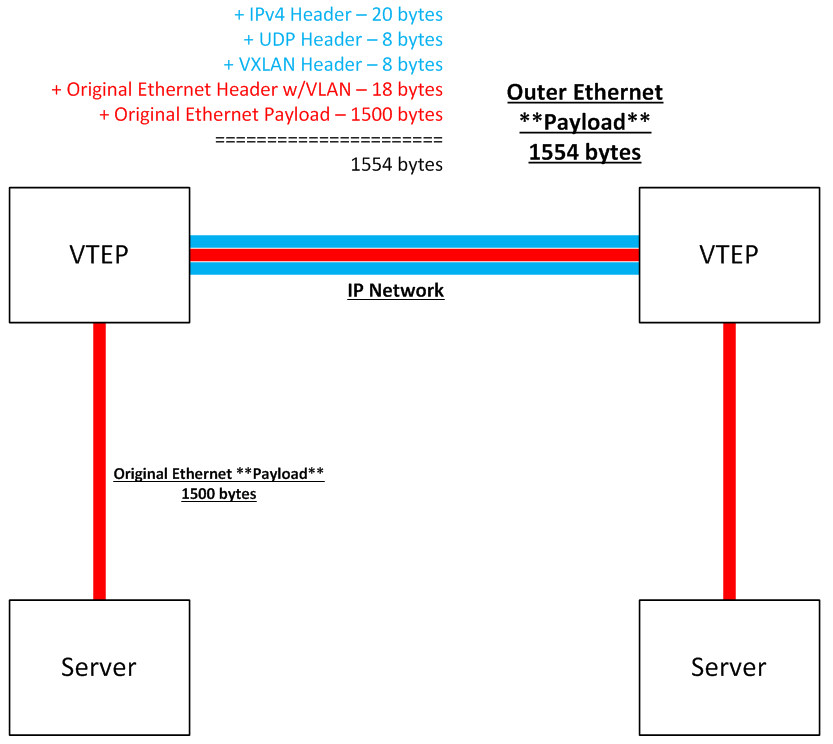
So, the math that we care about is as follows:
Outer IPv4 Header ----------- 20 bytes <==== assumes no extensions are used
Outer UDP Header ------------ 8 bytes
VXLAN Header ---------------- 8 bytes
Inner Ethernet Frame ------ 1518 bytes (max)
|
- 14 bytes for header, 4 bytes for 802.1q, 1500 for "inner inner" payload
=============================================
1554 bytes
Of course, IPv6 changes the game a little bit. The IPv6 header is twice the size of the IPv4 header, so with IPv6 it looks like this:
Outer IPv6 Header ----------- 40 bytes <==== assumes no extensions are used
Outer UDP Header ------------ 8 bytes
VXLAN Header ---------------- 8 bytes
Inner Ethernet Frame ------ 1518 bytes (max)
|
- 14 bytes for header, 4 bytes for 802.1q, 1500 for "inner inner" payload
=============================================
1574 bytes
The majority of those running VXLAN will likely be doing so over an IPv4 fabric, since (I believe) an IPv6 implementation of VXLAN is currently not supported by any implementation. (Sorry, IPv6-only data centers!)
Here’s a useful diagram that summarizes this. Note that a VTEP could be a physical switch, or a vSwitch.
Another habit we’ve picked up by running IPv4 for years is the compulsive need to block ICMP whenever possible. Take the Windows firewall, for instance. By default, it will block all ping requests until you disable it, or allow the traffic via a defined rule (guess which method is more common??).
Path MTU Discovery uses ICMP to discover the ACTUAL usable MTU on a network from end host to end host. This is a function built into any reasonably modern host networking stack. If a link MTU is 1500, but for some reason, the path to a host somewhere far away only supports 1400 (maybe one link out of hundreds is set to 1400) then the host networking stack will discover this with pMTU and won’t ever try to send frames larger than 1400.
Hopefully many of the IP networks upon which overlays are built will not traverse a firewall, rather than relying on distributed hypervisor-based firewalls for security, but in reality, some deployments will work this way.
If this is the case, don’t just ensure the right UDP port is open….also make sure that ICMP (and/or ICMPv6) is permitted for all VMs/hosts so that this function can be preserved. Keep in mind that you’re essentially building a mini-internet.
Implementations will vary, of course. This applies whether a physical or software-based VTEP. Of course, if no SDN-esque controller is present, then multicast mode is required for learning purposes (should use IGMP snooping and related features). If there’s a controller, unicast may be used.
While I’m at it, adding a controller can do something about MTU as well. For instance, a fabric built by Cisco Nexus 9000s will act like any routed fabric…you’ll have to counter for MTU like you would any other routed fabric. However, in ACI mode, these changes are made for us, in hardware, or even down to the vSwitch if using the AVS.
This post may get a few “duh"s out there for sure, but I’ve been burned by MTU issues before, and they don’t manifest themselves like any other network issue. It’s important to be aware of the environment where you’re deploying VXLAN. In reality, many organizations will be wary of moving completely to L3 topologies, and keeping some of the complex VLAN-based, firewall-wraught environments we have today. Be sure of your design and that you’re considering these, and all other important points to properly support overlay infrastructure.