Title here
Summary here
July 28, 2014 in Systems16 minutes
In the last post, I introduced you to the concept of control plane abstraction, specifically the OpenFlow implementation. I talked about how OpenFlow allows us to specify the flows that we want to be programmed into the forwarding plane, from outside the forwarding device itself. We can also match on fields we typically don’t have access to in traditional networking, since current hardware is optimized for destination-based forwarding.
In this post, I plan to cover quite a few bases. The goal of this post is to address the main concepts of OpenFlow’s operation, with links to find out more. With this post, you’ll be armed with the knowledge of what OpenFlow does and doesn’t do, as well as resources to dive even deeper.
NOTICE: This blog post was written referencing the specification and implementations of OpenFlow 1.3 - since this version, some aspects of the protocol may have changed (though it is likely the fundamentals discussed here will be mostly the same)
The OpenFlow specification describes a wide variety of topics. For instance, the protocol format that’s used to communicate with an OpenFlow switch by a controller is defined - in much the same way as you’d see in an IETF draft. However, the agent that receives OpenFlow instructions must also operate a certain way, and the OpenFlow specification addresses these concepts as well.
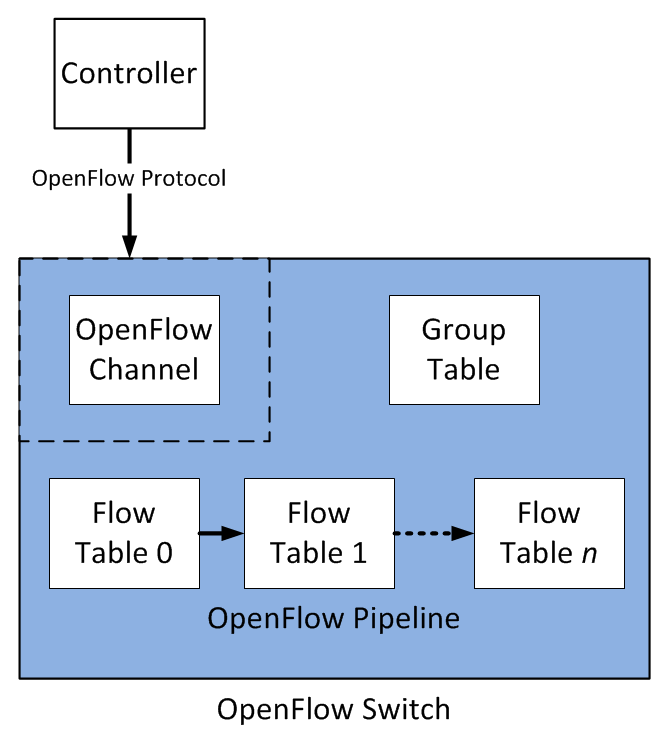
One such construct is OpenFlow Tables. You may have heard the term pipeline before. This is not an OpenFlow-centric term - the concept is often described in deep-dive sessions on internal switch architectures that explain the path a frame or packet takes through a switch. The myriad of systems used for internally processing a frame - such as regenerating a L2 header, identifying the next-hop destination, decrementing the TTL - all form a sort of “pipeline” that a frame travels through on it’s way out of the device.
The OpenFlow pipeline is meant to emulate this process in a vendor-agnostic way. Just like a hardware pipeline in a switch would be composed of multiple “stops” where various tasks are performed, the OpenFlow pipeline is composed of multiple tables that accomplish similar purposes.
In OpenFlow 1.0, only a single table was supported. Many recent efforts (e.g. OpenDaylight) have started to focus more on OpenFlow 1.3, which supports multiple tables, and is generally more popular and “feature-rich” than 1.0 in my opinion.
You could use one table for performing a port lookup, and another for making changes to the L3 header based off of it’s current information (NAT is a good example of this). Remember, OpenFlow is not a specific ASIC-level instruction-set, it is an abstraction that the switch creator must implement in a process that converts OpenFlow tables to hardware-specific instructions. It is up to the switch vendor to map the OpenFlow pipeline to specific hardware rules.
Current hardware pipelines are usually configured to support the “traditional” method of destination-based forwarding. We only care about destination MAC, or destination IP address in most cases. One of my first exposures to this paradigm is when I had to play around with Cisco Catalyst SDM Templates, which essentially re-organize TCAM resources to address the specific use case (Policy-Based Routing, or “Source Routing” in my case)
Tables are numbered, starting at 0. All packets go to 0 first, but can be directed to other tables as an Action - but only if that table’s ID is greater than it’s own (a.k.a. forward processing).
A great and easy way to see this in action is to spin up the demo Fedora 20 image that Kyle Mestery created for the community to learn OpenStack and OpenDaylight integration (Download here, walthrough here). In summary, the table layout for this implementation looks roughly like this:
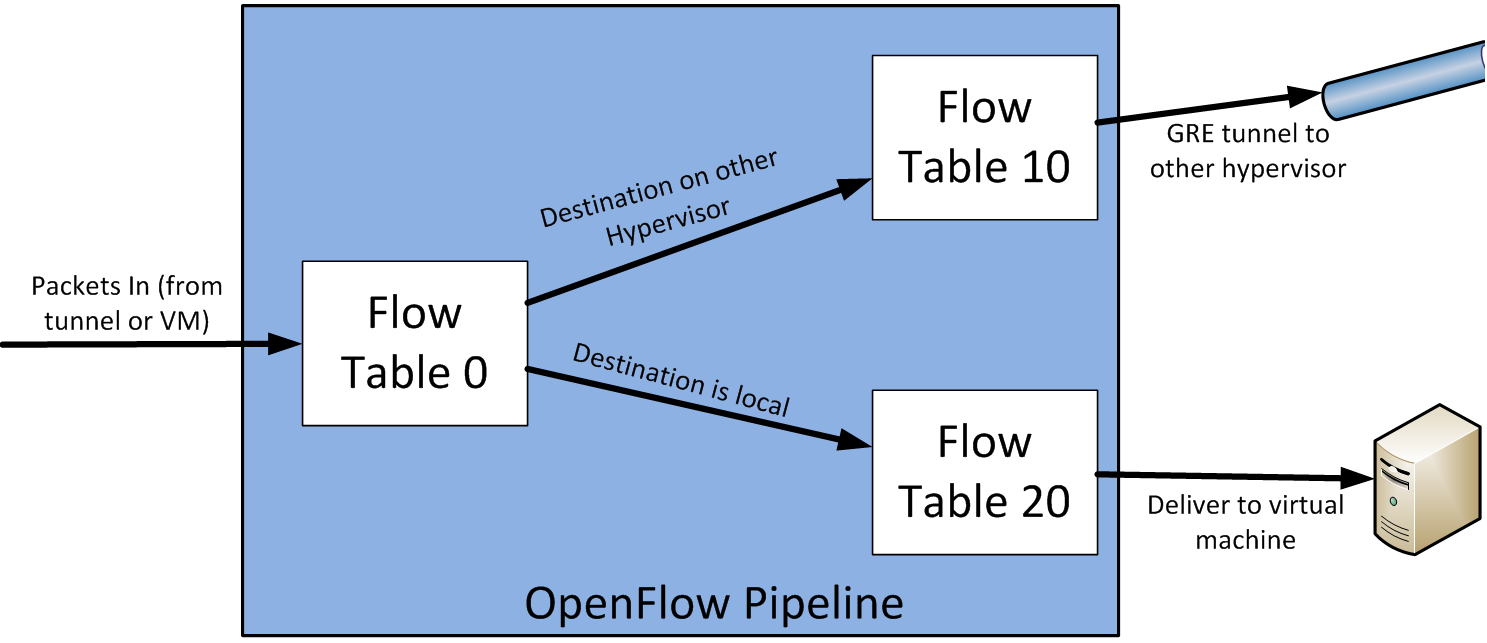
In essence, packets will enter the vSwitch (and in turn the OpenFlow pipeline) from either outside the hypervisor (usually a tunnel, if using overlays), or from a virtual machine. Either way, as the specification requires, all packets first go to table 0. In this specific demo, this table is used primarily for deciding if the traffic is destined for another hypervisor, or to a virtual machine local to this vSwitch. If the former, this table forwards to table 10, and if the latter, forwards to table 20. Both table 10 and 20 will apply any actions required (for instance, if the traffic needs to be NAT’d), but ultimately will forward the traffic out to the appropriate interface.
If you’re interested in the gory details, here’s the dump of the OpenFlow pipeline within a single OVS instance from that demo:
[odl@fedora-odl-control devstack-odl]$ sudo ovs-ofctl -O OpenFlow13 dump-flows br-int
OFPST_FLOW reply (OF1.3) (xid=0x2):
cookie=0x0, duration=642.651s, table=0, n_packets=30, n_bytes=2586, send_flow_rem tun_id=0x1,in_port=2 actions=goto_table:20
cookie=0x0, duration=563.287s, table=0, n_packets=30, n_bytes=2586, send_flow_rem in_port=3,dl_src=fa:16:3e:1c:fc:3b actions=set_field:0x1->tun_id,goto_table:10
cookie=0x0, duration=644.372s, table=0, n_packets=37, n_bytes=4198, send_flow_rem in_port=1,dl_src=fa:16:3e:e6:a8:9f actions=set_field:0x1->tun_id,goto_table:10
cookie=0x0, duration=562.906s, table=0, n_packets=0, n_bytes=0, send_flow_rem priority=8192,in_port=3 actions=drop
cookie=0x0, duration=644.197s, table=0, n_packets=0, n_bytes=0, send_flow_rem priority=8192,in_port=1 actions=drop
cookie=0x0, duration=4641.604s, table=0, n_packets=125, n_bytes=11125, send_flow_rem dl_type=0x88cc actions=CONTROLLER:56
cookie=0x0, duration=643.569s, table=10, n_packets=33, n_bytes=3356, send_flow_rem priority=8192,tun_id=0x1 actions=goto_table:20
cookie=0x0, duration=642.293s, table=10, n_packets=19, n_bytes=1614, send_flow_rem priority=16384,tun_id=0x1,dl_dst=01:00:00:00:00:00/01:00:00:00:00:00 actions=output:2,goto_table:20
cookie=0x0, duration=490.806s, table=10, n_packets=15, n_bytes=1814, send_flow_rem tun_id=0x1,dl_dst=fa:16:3e:c8:c8:26 actions=output:2,goto_table:20
cookie=0x0, duration=643.162s, table=20, n_packets=15, n_bytes=1814, send_flow_rem priority=8192,tun_id=0x1 actions=drop
cookie=0x0, duration=643.71s, table=20, n_packets=43, n_bytes=3658, send_flow_rem priority=16384,tun_id=0x1,dl_dst=01:00:00:00:00:00/01:00:00:00:00:00 actions=output:1,output:3
cookie=0x0, duration=643.931s, table=20, n_packets=24, n_bytes=2084, send_flow_rem tun_id=0x1,dl_dst=fa:16:3e:e6:a8:9f actions=output:1
cookie=0x0, duration=562.286s, table=20, n_packets=15, n_bytes=1814, tun_id=0x1,dl_dst=fa:16:3e:1c:fc:3b actions=output:3
As you can see, each table has several columns, for which each row must provide information. However, the columns that we’re interested in for the scope of this blog post are:
The other fields are important, but in this post, we will focus on matching flows, and doing stuff with them. I encourage you to check out the OpenFlow specification for the latest on supported fields, and what they do.
Now that you have seen the way OpenFlow tables interoperate, it’s time to look at how these tables identify flows based on fields in the various protocol headers, such as Ethernet, IP, and TCP. Before we can take action on a particular packet - such as determine forwarding behavior, or maybe make changes to the packet itself, we have to first identify the packets we want to do those things to.
Matching is fairly straightforward - a given flow will contain a list of fields and what those fields should equal if they are to be considered in the flow that entry is describing. Any packets that are matched by that flow will have all the instructions contained within that flow applied to them.
The OpenFlow specification has a list of common fields that a compliant pipeline must support (In the OpenFlow 1.3.2 spec, this is section 7.2.3.7). However, specific implementations are free to go above and beyond this minimum requirement, provided that requirement is met. For instance, Open vSwitch has a published document on all of the fields it is capable of matching on.
Matches are also locally significant within an OpenFlow pipeline. If a previous table changed a packet in any way, then the current table’s match fields reflect those changes.
If a packet matches multiple flow entries, only the one with the highest priority is used. Flow entries with many match statements are typically called “Fine Flows”, and those with relatively fewer match statements are referred to as “Coarse Flows”. This is of course not part of a specification, but some lingo I picked up when first exploring OpenFlow a few years ago.
A table’s “table-miss flow” entry can specify what to do with packets that don’t otherwise match a flow entry in that table. If no such entry exists, that packet is dropped, similar to the invisible implicit “deny all” found at the end of many types of access-control lists. For instance, line 8 in the flow table printed in the last section sends packets to the controller for inspection - and it is the last entry in Table 0.
Early versions of OpenFlow used a fixed length structure for match statements, and was therefore pretty inflexible. As of OpenFlow 1.2, a TLV structure was adopted, which allows matches to be added in a much more modular way. These are called OpenFlow Extensible Match, or OXMs. In short, these are the fields that the specification allows you to match on. OXM should be thought of as a new format for describing field matches.
Section 7.2.3.7 in the OpenFlow 1.3.2 specification describes all of the OXMs you can match on in this version.
OXMs were initially referred to as NXMs, which stands for Nicira Extensible Match (Nicira obviously now a part of VMware). This is because NXMs formed the basis for OXMs, and were made to be part of the specification as of version 1.2. However, some NXM definitions are still around, as additional definitions are pushed into platforms like Open vSwitch. For instance, there was a time that IPv6 fields were not specified within the OpenFlow specification, but were supported by NXMs via platforms like OVS.
Of course, the point of matching on a particular flow is to be able to do interesting things to packets in that particular flow. For instance, we might want to forward certain packets out a tunnel interface, or maybe apply some security policies. OpenFlow has some interesting constructs to support this functionality, and it’s easy to get the terminology mixed up.
The fundamental concept here is the Action. These are as you would expect - something you want to do with a given packet. This might mean decrementing the TTL of an IP header, or forwarding out an interface. It might also mean appending a new header - for instance, an MPLS label.
Each packet will have an Action Set associated with it. This is simply a list of Actions, and this list will follow a packet through the pipeline. This Action Set is applied when there are no more “Goto-Table” instructions, which typically means the packet has reached the end of the pipeline.
The order in which these changes are applied is important to consider. Changes are made in a very specific order. For instance an inward TTL copy action will occur before popping an MPLS tag in the action set. For the full list and order, see section 5.10 in the OpenFlow 1.3.2 specification. The final action in this set could be an “output” action (i.e. forward out a port) or a “group” action, in which case the packet receives the actions of the relevant group bucket. Those actions are also bound by the order of operations mentioned above. If a group is given, the output action is ignored (since there are more actions to take place within that group).
There are some important points here, so as mentioned before, I really encourage you to read the section on Action Sets (in OF spec 1.3.2 this is section 5.10) - some important caveats and points are made in this section.
Action Lists are very similar to Action Sets, but are useful if you want to apply a list of actions to a packet immediately at it’s current place in the pipeline, without modifying the existing Action Set. The “Apply-Actions” instruction (which we’ll discuss next) takes an argument of an Action List and applies those actions immediately. After these actions are applied on a given packet, that packet continues through the pipeline, without having it’s own Action Set changed.
Dave Tucker was kind enough to also point out that set-field actions can only occur once (setting a value to a field twice would obviously overwrite the first value). For examples like pushing a new MPLS label, you’d want to use Action Lists (with the Apply-Actions instruction). Since this happens immediately, you could match on these fields in the next table. (Thanks, Dave!)
Finally, Instructions bring all of this together. Instructions can do several things, but the two required instructions is “Write-Actions”, which merges specified action(s) into the existing Action Set, and “Goto-Table”, which sends a packet to another table in the pipeline. These two core functions are designed to move a packet through a pipeline, and if at the end, ultimately do something with the packet. As mentioned before, an instruction can optionally apply actions midway through the pipeline through the “Apply-Actions” instruction. There are a few other optional instructions contained in the OpenFlow specification.
Hopefully that was clear - these terms are laid out in the specification but it is easy to get the streams crossed. With this framework, we can effectively treat packets within an OpenFlow pipeline and get them on their way.
So let’s say you have a set of flows you wish to enforce. Whether you’re manually programming flows into a controller, or tying that controller into a higher entity like OpenStack in order to provide network state, the controller needs to be able to provide those flows to the necessary forwarding devices.
This is where the term “Flow Instantiation” comes about. Similarly to how programmers instantiate a certain class, we need to create an instance of the flows we’ve defined at the controller layer, down at the data plane. This can happen via one of two methods.
The first method is known as Reactive Flow Instantiation. In this model, the controller is aware of all of the flows pushed into it by higher entities, but does not make an extra effort to push these down to the data plane. When the data plane receives a packet that it doesn’t have a local match for, the entire packet is sent up to the controller from that forwarding element. The controller then responds with a decision, and the data plane keeps this flow entry so that future packets in this flow can happen without controller intervention. If you’ve ever gone through a CCNP SWITCH course or equivalent, you may see some similarities with Fast Switching, where the first packet in a particular conversation is punted to a software process for a decision, but all other packets are hardware switched.
You may have heard OpenFlow terms like “Packet-In” - this is the event where the original packet that did not match a local flow on the forwarding element is forwarded to the controller for a decision. “Packet-out” describes an event where the controller sends it’s own packets downstream to be forwarded out a certain port.
The second method is Proactive Flow Instantiation. In this mode, the controller proactively pushes all flows into the forwarding elements. This is popular when performing integrations with virtualized or cloud workloads, since the network information for these workloads is already known, and can therefore get pushed into the network immediately when a virtual machine or container is spun up. These flows can also be immediately deleted when the workloads are decommissioned.
These days, a very popular method is a hybrid of the two, where all known flows are proactively pushed into the data plane, but reactive mode is permitted. This at least gives the controller the ability to make decisions for packets that didn’t match a flow. So instead of omitting a table-miss flow, a controller might insert a rule that punts packets that don’t match a particular flow to the controller for a decision.
A very large portion (not all) of arguments against OpenFlow, specifically those concerning scalability, assume a totally reactive model, in which the first packet of every single flow are forwarded to the controller. I think it’s widely understood that this is not ideal, and it is a best practice to use proactive instantiation whenever possible.
The OpenDaylight controller permits Reactive Flows by default, but in most integration efforts, such as with OpenStack Neutron, all relevant flows are pushed proactively, so while reactive flows are permitted, they are rare.
If you want to know more about this aspect of OpenFlow, I highly recommend Brent Salisbury’s post on the subject.
Most switches that support OpenFlow also have their own control plane. So on the surface, I originally assumed this required a coexistence of an OpenFlow pipeline and a hardware-specific pipeline within a single device.
Vendors appear to be tackling this problem in a variety of ways. I recommend you check out Ivan’s post on OpenFlow deployment models. The post is from 2011, but it still accurately captures the majority of models that we’re starting to see in the wild.
Historically, vendors used the ships-in-the-night approach (some still do), where OpenFlow runs as a completely separate process, and you can assign ports to use the “old” model, or the OpenFlow model, but not both. As Ivan says, this is a fairly low-risk approach, since it allows you to dedicate a portion of your network for R&D without affecting the rest. When learning of this method, it reminded me greatly of Cisco’s VDC feature, where you can virtualize an entire NX-OS instance and allocate physical ports to it.
The “integrated” approach seems to be increasing in popularity. In this model, the existing control plane continues to operate on a networking device, with all (or most) of the features that have been there for a long time. OpenFlow support is also offered, which means that the OpenFlow pipeline cannot simply be translated directly into hardware - the vendor has to figure out how to merge the two “competing” pipelines into a single forwarding plane.
This was the topic of choice for a GREAT Tech Field Day moment that I have bookmarked and continue to revisit:
A very popular deployment model is to use OpenFlow almost totally within a virtual switching context (i.e. within a hypervisor), and rely on the physical infrastructure for nothing more than IP transport - for instance, to support an overlay like VXLAN. In order to support OpenFlow-based service insertion for physical workloads, however, a physical switch is obviously needed. It ultimately depends on where your workloads are, and how much granular control you need over them.
I mentioned in the section about OpenFlow Tables that each vendor must interpret the OpenFlow pipeline themselves, in order to place that pipeline into a meaningful pipeline on their switch (or vSwitch). As you can imagine, every vendor does things differently with respect to the internal switch pipeline, and some of the features in one chip may not exist in another chip, or may be implemented too differently to map consistently.
OpenFlow operates in much the same way that virtualized hardware and drivers inside of a virtual machine don’t need to know the actual underlying hardware - the hypervisor takes care of that. Similarly, OpenFlow rules are not specific to the hardware itself, but rather generalized. This tends to be the focus of many OpenFlow nay-sayers, since this essentially means that OpenFlow must cater to the common denominator of hardware features. I’ll leave it to you to draw your own conclusions there.
Nonetheless, it is an issue that many folks are considering. Today, most OpenFlow controllers will attempt to send an OpenFlow match or action down to the data plane, and if the data plane does not support that feature, it will respond with an error saying so. Instead of this, the ONF Forwarding Abstractions Working Group (FAWG) has published info on Table Type Patterns (TTPs) which is roughly equivalent to a negotiation protocol between the controller and the data plane, in which the data plane is able to report what specific features it is able to support.
Colin Dixon and Curt Beckmann did a great presentation on this topic at the OpenDaylight Summit back in February, and provides a great introduction to this concept:
I hope this deep-dive was useful. Whether you deploy OpenFlow in your environment or not, there is no denying that this single protocol was the tip of the spear that’s been disrupting this industry for the past 5 years or so. Even if OpenFlow as a protocol ceases to be a focus in the SDN conversation in the future, it was instrumental in getting network professionals to think about their network in an abstract way, and begin to close the gap between infrastructure and application.
Of course, I can only get so deep in a single blog post, so I encourage you to visit the resources I’ve linked to throughout this blog post. Some of the more important links are listed below: