Title here
Summary here
November 7, 2014 in Systems4 minutes
I am in the Bay Area this week, working on some network automation stuff, and I was fortunate to be able to stop by and say hello to the Storage Field Day 6 folks over drinks.
I was told by several impressed delegates about a talk by Andy Warfield of Coho Data, where he described how they used OpenFlow to steer storage traffic intelligently to and from various nodes in a distributed storage array.
For the majority of the discussion, he talks at length about how NICs have long been able to push more data than a single CPU core is able to process, and as a result, they have to be intelligent about the distribution of packet processing onto the cores within a multicore system.
In summary, a big problem with file-based storage systems is dealing with load sharing. NFS clients have to point to an IP address where the exports are located, and if this IP address was available only on a single NIC on a storage array, this pretty severely limits your options - that port becomes a big bottleneck. I’ve seen some customers assign IP addresses to several ports on an array, and use them in rotations when configuring clients. This also has issues, and is a pain from a management perspective.
Beyond all this - the discussion isn’t even about even load-sharing across an array. It’s also about getting requests to arrive closer to the data that is being accessed. When Coho’s solution was initially explained to me, I asked why they didn’t just use some kind of ARP-based redundancy protocol to distribute storage requests. Based on certain load and meta-data characteristics, the storage array could intelligently direct clients to it’s network endpoints.
However, this still isn’t sufficient when you consider how dynamic storage requirements (both inside and outside the array) can be. Most of the time, gratuitous ARPs are used to quickly upstream changes to a L2 topology, but there’s more to this than that. Coho wanted to be able to accept requests on one interface, and send the responses out another interface, presumably closer to the workload.
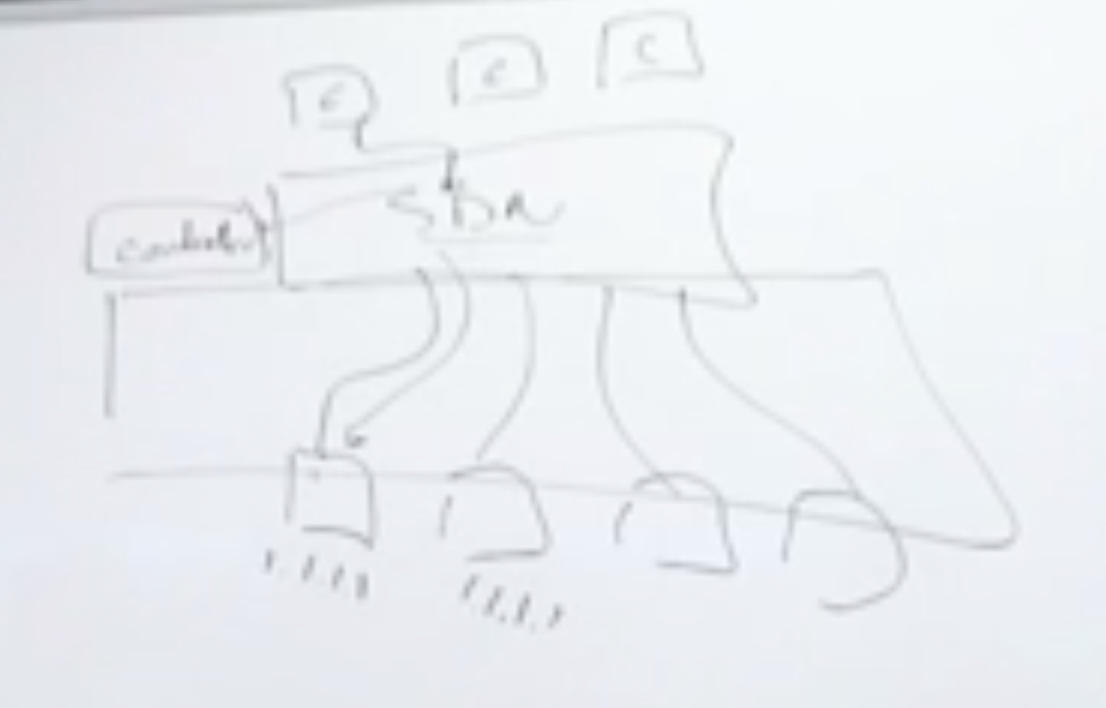
Coho decided to use OpenFlow to solve this problem - they’ve effectively turned the entire storage array into a distributed TCP endpoint. Requests arrive on a single interface (and are inherently quite small). If the data being accessed is on a different endpoint on the array, the request is forwarded back through the network to that endpoint. This is actually pretty common, because most vendors have some kind of optimization in place. However, the response, containing the actual data, must be sent back to the original array endpoint interface somehow, because that’s where NFS clients are expecting the data to come from.
Because of the switch implementation, they are able to respond to a request on a different interface than the request originally arrived on. Using OpenFlow on the switch, Coho can track TCP connections, and translate L2 information to hide the fact that responses are coming from a different interface.
The end result, is of course, better performance. Responding to requests closer to where the data is stored, but without the compromise of going back through a “middle-man” hop on the array, means you get the best of both worlds. I’d be interested in seeing numbers from actual deployments of this - most of what us networking folks have come to realize as some OpenFlow limitations shouldn’t be a big deal in a limited deployment like this, so I’m quite intrigued. Please comment below if you have any more information I can look over!
I was not a delegate of Storage Field Day 6, but have been a delegate at several Networking Field Day events, and as is typical at these events, some expenses, such as travel, has been covered before by vendors. However, in this case, I was just in the area for a work project, and came across this information in the course of conversation. As usual, I am not influenced in any way by any vendor to write anything - I write about stuff I find interesting.