Title here
Summary here
November 4, 2020 in Programming24 minutes
Even though I’ve developed software for a number of years now, there’s one question that has always been in the back of my mind and I haven’t had the time or patience to really answer, until now: What is a binary executable anyways?
For this example, I wrote a brutally simple Rust program that includes a function “sum” to add two integers together, and am invoking it from main():
My Rust code is always structured the “cargo way”, so I can compile my program by running cargo build, and this will produce a binary for me within the target/debug/ directory. I have named my crate rbin, so this is the name of the binary that is created at this location:
These days, it’s really easy to take such questions for granted, but if you’re curious, you may be asking:
“But what is that file?”
I mean we all generally know that it’s an “executable”, in that we run it and our program happens. But what does that mean? What is contained in that file that means our computer automatically just knows how to run it? And how is it possible that a program with 7 lines of code can take up over 3 megabytes of disk space?!?
It turns out that in order to create an executable for this ridiculously simple program, the Rust compiler must include quite a bit of additional software to make it possible.
Well, it turns out there is a widely accepted format for these things, called the “Executable and Linkable Format”, or ELF!
Note that I won’t be comprehensively covering ELF here (there are plenty of other resources, many of which I’ll link to) - rather this is an exploration of what goes into a Rust binary with the simplest, default settings, and some observations about what seems interesting to me.
ELF is a well-known, popular format, especially in the world of Linux, but there are plenty of others. Operating systems like Windows and macOS each have their own format, which is a big reason why, when you’re compiling (or simply downloading) software, you have to specify the operating system you want to run it on. This is true despite the fact that the underlying machine code that executes your program may be the same on all of them (e.g. x86_64).
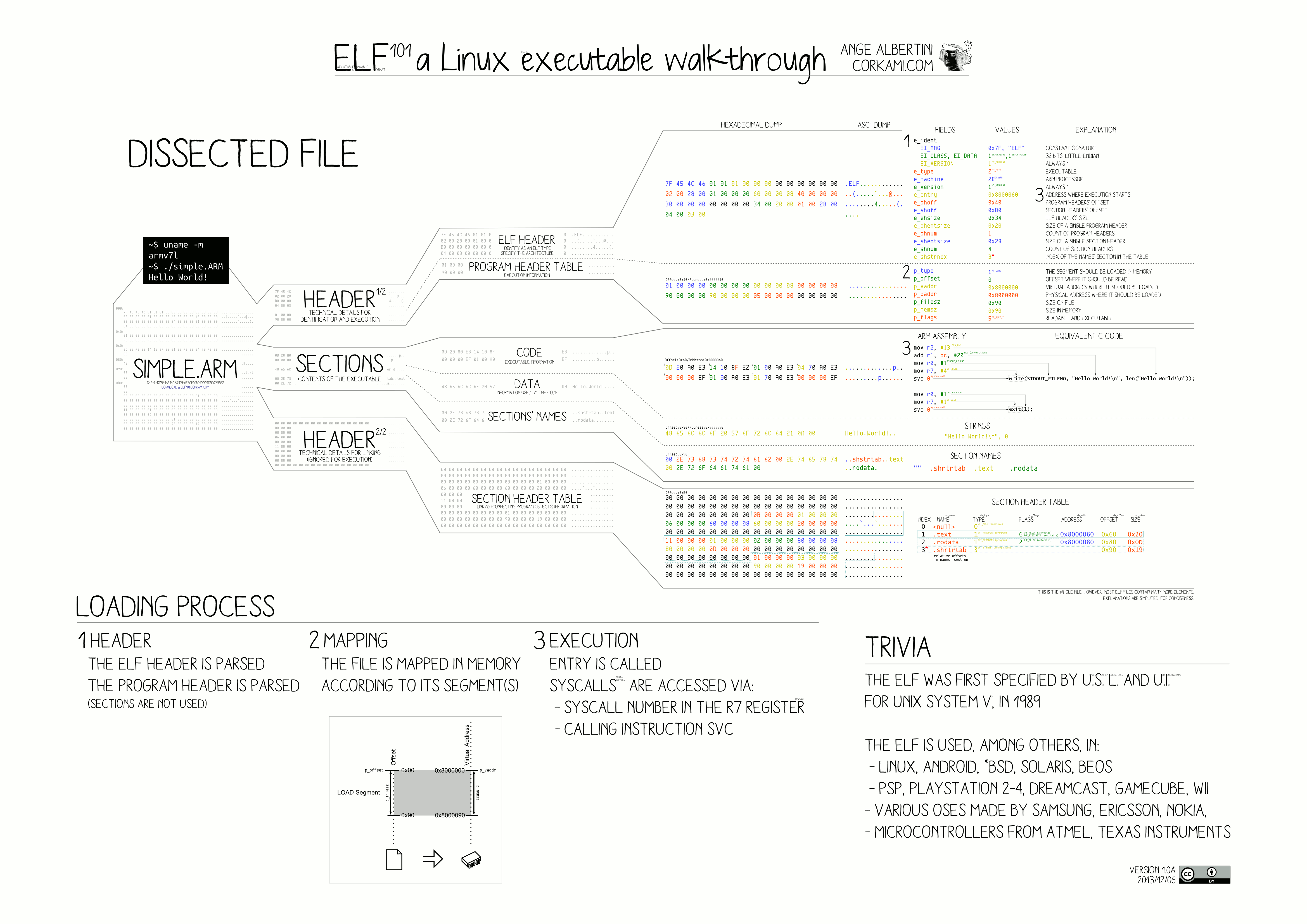
An exceptional visual breaking down the ELF format can be found at the link to the ELF wikipedia page above, I have found myself constantly referring back to it while writing this post:
Commonly, executable formats like this specify a magic number right at the beginning of the file, so that the format can be easily identified. This occupies the first four bytes in the file header. This is a very important field, because unless we can first identify an ELF file appropriately, we can’t reasonably expect to do anything “ELF-y” with it. We know where certain bits of information should be in an ELF file, but we first must identify using these bytes that this is what we can expect.
The readelf utility is extremely useful for printing all kinds of useful metadata and related tables of information contained within an ELF file. However, this utility expects - naturally - that the file being read is actually an ELF file, and even provides a helpful hint that the expected “magic bytes” for a non-ELF file aren’t set appropriately when used on a non-ELF file, so it doesn’t attempt to read the rest:
Once identified, the entire rest of the file can be identified using byte offsets (that is, the number of bytes from zero).
For those that are accustomed to looking at network packet captures, this should all sound very familiar to you, as this is exactly how we know where certain fields are located in a packet header. Ethernet frames have a predictable preamble and start-of-frame delimiter. Ethernet also has a field called the “Ethertype”, which provides a clue as to what protocol is contained within the Ethernet frame (which allows computers to then parse those field as well). Just like Ethernet has a standard set of byte offsets that indicate where the various fields should be represented, the ELF format specifies its own offsets for all of the fields providing useful identifying and execution information in the file header, which then point to other important locations within the file.
There’s all kinds of useful information in this header, but in particular, the e_entry field in the file header points to the offset location from where the execution should start. This is the “entry point” for the program. We’ll definitely be following this down the rabbit hole in a little bit.
We can again use readelf, this time on a proper ELF file (our Rust program), and also using the -h flag to show the file header:
1~$ readelf -h target/debug/rbin
2
3ELF Header:
4 Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
5 Class: ELF64
6 Data: 2's complement, little endian
7 Version: 1 (current)
8 OS/ABI: UNIX - System V
9 ABI Version: 0
10 Type: DYN (Shared object file)
11 Machine: Advanced Micro Devices X86-64
12 Version: 0x1
13 Entry point address: 0x5070
14 Start of program headers: 64 (bytes into file)
15 Start of section headers: 3195368 (bytes into file)
16 Flags: 0x0
17 Size of this header: 64 (bytes)
18 Size of program headers: 56 (bytes)
19 Number of program headers: 12
20 Size of section headers: 64 (bytes)
21 Number of section headers: 42
22 Section header string table index: 41So, the “magic number” lets us parse at least the rest of the file header, which contains not only information about the file, but byte-offset locations for other important portions of the file. One of these is the “Start of program headers”, which starts after 64 bytes.
The program header table contains information that allows the operating system to allocate memory and load the program. This is also referred to as a process image. You can think of it as a list of “instructions” that tell the system to do various things with chunks of memory in order to prepare to execute this program.
The readelf utility also allows us to read the program headers using the -l flag:
1~$ readelf -l target/debug/rbin
2
3Elf file type is DYN (Shared object file)
4Entry point 0x5070
5There are 12 program headers, starting at offset 64
6
7Program Headers:
8 Type Offset VirtAddr PhysAddr
9 FileSiz MemSiz Flags Align
10 PHDR 0x0000000000000040 0x0000000000000040 0x0000000000000040
11 0x00000000000002a0 0x00000000000002a0 R 0x8
12 INTERP 0x00000000000002e0 0x00000000000002e0 0x00000000000002e0
13 0x000000000000001c 0x000000000000001c R 0x1
14 [Requesting program interpreter: /lib64/ld-linux-x86-64.so.2]
15 LOAD 0x0000000000000000 0x0000000000000000 0x0000000000000000
16 0x0000000000004ed8 0x0000000000004ed8 R 0x1000
17 LOAD 0x0000000000005000 0x0000000000005000 0x0000000000005000
18 0x0000000000030571 0x0000000000030571 R E 0x1000
19 LOAD 0x0000000000036000 0x0000000000036000 0x0000000000036000
20 0x000000000000be44 0x000000000000be44 R 0x1000
21 LOAD 0x0000000000042520 0x0000000000043520 0x0000000000043520
22 0x0000000000002b18 0x0000000000002cf8 RW 0x1000
23 DYNAMIC 0x0000000000044740 0x0000000000045740 0x0000000000045740
24 0x0000000000000230 0x0000000000000230 RW 0x8
25 NOTE 0x00000000000002fc 0x00000000000002fc 0x00000000000002fc
26 0x0000000000000044 0x0000000000000044 R 0x4
27 TLS 0x0000000000042520 0x0000000000043520 0x0000000000043520
28 0x0000000000000000 0x00000000000000d8 R 0x20
29 GNU_EH_FRAME 0x000000000003aa8c 0x000000000003aa8c 0x000000000003aa8c
30 0x0000000000000d84 0x0000000000000d84 R 0x4
31 GNU_STACK 0x0000000000000000 0x0000000000000000 0x0000000000000000
32 0x0000000000000000 0x0000000000000000 RW 0x10
33 GNU_RELRO 0x0000000000042520 0x0000000000043520 0x0000000000043520
34 0x0000000000002ae0 0x0000000000002ae0 R 0x1
35
36 Section to Segment mapping:
37 Segment Sections...
38 00
39 01 .interp
40 02 .interp .note.gnu.build-id .note.ABI-tag .gnu.hash .dynsym .dynstr .gnu.version .gnu.version_r .rela.dyn .rela.plt
41 03 .init .plt .plt.got .text .fini
42 04 .rodata .debug_gdb_scripts .eh_frame_hdr .eh_frame .gcc_except_table
43 05 .init_array .fini_array .data.rel.ro .dynamic .got .data .bss
44 06 .dynamic
45 07 .note.gnu.build-id .note.ABI-tag
46 08 .tbss
47 09 .eh_frame_hdr
48 10
49 11 .init_array .fini_array .data.rel.ro .dynamic .got Each program header type does something different to a chunk of memory (segment). Next to each header can be found two 64-bit (this is a 64 bit ELF after all) hexidecimal values. As indicated at the top of the header output, the top value is the memory offset of the segment that the header refers to (where it is located). The value below that is the size of that particular segment in the file.
Each segment is further subdivided into sections, which we’ll get to later. For now, notice the “section to segment mapping” table below the program headers. See how they’re numbered? These numbers correspond to the position of the program headers above. So, the first header (which happens to be of type PHDR) is referring to segment 00, the second (which happens to be INTERP) to 01, and so on.
A full summary of program header types can be found here, but a brief explanation of each segment of our actual program and what the corresponding header type is indicating should be done with that segment can be found below:
| Segment Number | Header Type | Explanation |
|---|---|---|
| 00 | PHDR | Indicates the location and size of the program header table itself |
| 01 | INTERP | Provides the location of an interpreter on the system, used for dynamic linking. This allows us to simply use the libraries on the system, rather than having to compile all of these libraries into the binary (this is called static linking) |
| 02-05 | LOAD | These segments are be loaded into memory. Note that segment 03 has the E flag set, which indicates this is where our executable code lives. |
| 06 | DYNAMIC | Provides dynamic linking information, such as which libraries on the system the interpreter needs to provide access to at runtime. |
| 07 | NOTE | This is commonly used to store things like the ABI (and version) used in this program to communicate with the underlying operating system. |
| 08 | TLS | Thread-local storage |
| 09 | GNU_EH_FRAME | Frame unwind information. Used for exception handling |
| 10 | GNU_STACK | Used for explicitly requesting that the stack is executable (note in the output above, this bit is not set) |
| 11 | GNU_RELRO | Specifies the region of memory that should be read-only once loading (relocation) has taken place |
We now have a better sense for what the Rust compiler feels should be included in the program header table - specifically how Rust recommends our computer prepares itself to run the program that we’ve compiled - again, in the simplest, default case. Some takeaways from this:
readelf when we saw the INTERP header type for segment 01, we saw a sneak preview of the interpreter that is being requested, /lib64/ld-linux-x86-64.so.2. You can actually run this yourself and it will tell you a little bit about itself. Pretty cool!INTERP and DYNAMIC header types implies that dynamic linking is the default when compiling Rust programs, which isn’t weird - lots of compiled languages force you to specify if you want a statically linked binary.The section header table is usually located near the end of an ELF file, and its main job is to provide information for linking purposes, but I also found it useful to understand the contents of each section - in particular, the size of each:
1~$ readelf -S target/debug/rbin
2There are 42 section headers, starting at offset 0x30c1e8:
3
4Section Headers:
5 [Nr] Name Type Address Offset
6 Size EntSize Flags Link Info Align
7 [ 0] NULL 0000000000000000 00000000
8 0000000000000000 0000000000000000 0 0 0
9 [ 1] .interp PROGBITS 00000000000002e0 000002e0
10 000000000000001c 0000000000000000 A 0 0 1
11 [ 2] .note.gnu.build-i NOTE 00000000000002fc 000002fc
12 0000000000000024 0000000000000000 A 0 0 4
13 [ 3] .note.ABI-tag NOTE 0000000000000320 00000320
14 0000000000000020 0000000000000000 A 0 0 4
15 [ 4] .gnu.hash GNU_HASH 0000000000000340 00000340
16 0000000000000024 0000000000000000 A 5 0 8
17 [ 5] .dynsym DYNSYM 0000000000000368 00000368
18 0000000000000720 0000000000000018 A 6 1 8
19 [ 6] .dynstr STRTAB 0000000000000a88 00000a88
20 000000000000052d 0000000000000000 A 0 0 1
21 [ 7] .gnu.version VERSYM 0000000000000fb6 00000fb6
22 0000000000000098 0000000000000002 A 5 0 2
23 [ 8] .gnu.version_r VERNEED 0000000000001050 00001050
24 00000000000000f0 0000000000000000 A 6 4 8
25 [ 9] .rela.dyn RELA 0000000000001140 00001140
26 0000000000003d50 0000000000000018 A 5 0 8
27 [10] .rela.plt RELA 0000000000004e90 00004e90
28 0000000000000048 0000000000000018 AI 5 26 8
29 [11] .init PROGBITS 0000000000005000 00005000
30 000000000000001b 0000000000000000 AX 0 0 4
31 [12] .plt PROGBITS 0000000000005020 00005020
32 0000000000000040 0000000000000010 AX 0 0 16
33 [13] .plt.got PROGBITS 0000000000005060 00005060
34 0000000000000008 0000000000000008 AX 0 0 8
35 [14] .text PROGBITS 0000000000005070 00005070
36 00000000000304f3 0000000000000000 AX 0 0 16
37 [15] .fini PROGBITS 0000000000035564 00035564
38 000000000000000d 0000000000000000 AX 0 0 4
39 [16] .rodata PROGBITS 0000000000036000 00036000
40 0000000000004a69 0000000000000000 A 0 0 16
41 [17] .debug_gdb_script PROGBITS 000000000003aa69 0003aa69
42 0000000000000022 0000000000000001 AMS 0 0 1
43 [18] .eh_frame_hdr PROGBITS 000000000003aa8c 0003aa8c
44 0000000000000d84 0000000000000000 A 0 0 4
45 [19] .eh_frame PROGBITS 000000000003b810 0003b810
46 00000000000049e0 0000000000000000 A 0 0 8
47 [20] .gcc_except_table PROGBITS 00000000000401f0 000401f0
48 0000000000001c54 0000000000000000 A 0 0 4
49 [21] .tbss NOBITS 0000000000043520 00042520
50 00000000000000d8 0000000000000000 WAT 0 0 32
51 [22] .init_array INIT_ARRAY 0000000000043520 00042520
52 0000000000000010 0000000000000008 WA 0 0 8
53 [23] .fini_array FINI_ARRAY 0000000000043530 00042530
54 0000000000000008 0000000000000008 WA 0 0 8
55 [24] .data.rel.ro PROGBITS 0000000000043538 00042538
56 0000000000002208 0000000000000000 WA 0 0 8
57 [25] .dynamic DYNAMIC 0000000000045740 00044740
58 0000000000000230 0000000000000010 WA 6 0 8
59 [26] .got PROGBITS 0000000000045970 00044970
60 0000000000000678 0000000000000008 WA 0 0 8
61 [27] .data PROGBITS 0000000000046000 00045000
62 0000000000000038 0000000000000000 WA 0 0 8
63 [28] .bss NOBITS 0000000000046038 00045038
64 00000000000001e0 0000000000000000 WA 0 0 8
65 [29] .comment PROGBITS 0000000000000000 00045038
66 000000000000002a 0000000000000001 MS 0 0 1
67 [30] .debug_aranges PROGBITS 0000000000000000 00045062
68 0000000000008700 0000000000000000 0 0 1
69 [31] .debug_pubnames PROGBITS 0000000000000000 0004d762
70 00000000000479a9 0000000000000000 0 0 1
71 [32] .debug_info PROGBITS 0000000000000000 0009510b
72 00000000000ba088 0000000000000000 0 0 1
73 [33] .debug_abbrev PROGBITS 0000000000000000 0014f193
74 000000000000102c 0000000000000000 0 0 1
75 [34] .debug_line PROGBITS 0000000000000000 001501bf
76 000000000005f7cd 0000000000000000 0 0 1
77 [35] .debug_frame PROGBITS 0000000000000000 001af990
78 00000000000001f0 0000000000000000 0 0 8
79 [36] .debug_str PROGBITS 0000000000000000 001afb80
80 00000000000ce162 0000000000000001 MS 0 0 1
81 [37] .debug_pubtypes PROGBITS 0000000000000000 0027dce2
82 000000000000068b 0000000000000000 0 0 1
83 [38] .debug_ranges PROGBITS 0000000000000000 0027e36d
84 000000000007e400 0000000000000000 0 0 1
85 [39] .symtab SYMTAB 0000000000000000 002fc770
86 00000000000055f8 0000000000000018 40 642 8
87 [40] .strtab STRTAB 0000000000000000 00301d68
88 000000000000a2cb 0000000000000000 0 0 1
89 [41] .shstrtab STRTAB 0000000000000000 0030c033
90 00000000000001b1 0000000000000000 0 0 1
91Key to Flags:
92 W (write), A (alloc), X (execute), M (merge), S (strings), I (info),
93 L (link order), O (extra OS processing required), G (group), T (TLS),
94 C (compressed), x (unknown), o (OS specific), E (exclude),
95 l (large), p (processor specific)If you convert the size of each section from hex to decimal, and add them up, you get 3190428 (bytes), which is really close to the total size of the file of 3198056, as reported by ls. So with this section table, we can start to get a sense a for where all that data is coming from, and an idea of where to poke around next.
I’ll leave it here for now, but this lesson gives a really good overview of this table.
So now what? What actually executes?
While readelf does have some flags for inspecting the contents of these sections, we’ll instead use a tool called objdump which does a much better job of showing the breakdown of each section’s contents, both in raw hexidecimal opcodes and arguments, as well as the interpreted assembly:
1objdump -d -C target/debug/rbin -EL -M intel --insn-width=8 | lessSome pointers on the flags I’m passing:
-d flag instructs objdump to disassemble all executable sections. This will produce assembly instructions next to the corresponding machine code in the output.-C target/debug/rbin points to the location of the binary to disassemble.-M intel specifies the Intel format should be used when interpreting the machine code and displaying into assembly--insn-width=8 is an aesthetic preference for me - I like the machine code to be displayed on one line, and sometimes it can be 8 bytes long (the default is 7)| less pipes the output to less, which allows me to look through the output with arrow keys, and move up and down, and search with ease.The
-Sflag interleaves the rust source code within the assembly so we can see exactly what lines of Rust resulted in which lines of machine code. I left this out because I’ll be explaining the relevant lines myself, and it keeps the examples more simple-looking, but definitely use this flag on your own, as it was very helpful for me.
In the file header we saw there was a reference to an entry point in memory. As a reminder, this was 0x5070. Once the file header and program headers are parsed, and the segments loaded into memory, the computer will start running instructions, beginning at this position. So let’s scroll to that position in the output of objdump and use that as our starting point. Note that this can be found within the .text section we looked at just previously:
1Disassembly of section .text:
2
30000000000005070 <_start>:
4 5070: f3 0f 1e fa endbr64
5 5074: 31 ed xor ebp,ebp
6 5076: 49 89 d1 mov r9,rdx
7 5079: 5e pop rsi
8 507a: 48 89 e2 mov rdx,rsp
9 507d: 48 83 e4 f0 and rsp,0xfffffffffffffff0
10 5081: 50 push rax
11 5082: 54 push rsp
12 5083: 4c 8d 05 b6 04 03 00 lea r8,[rip+0x304b6] # 35540 <__libc_csu_fini>
13 508a: 48 8d 0d 3f 04 03 00 lea rcx,[rip+0x3043f] # 354d0 <__libc_csu_init>
14 5091: 48 8d 3d 38 03 00 00 lea rdi,[rip+0x338] # 53d0 <main>
15 5098: ff 15 92 0b 04 00 call QWORD PTR [rip+0x40b92] # 45c30 <__libc_start_main@GLIBC_2.2.5>
16 509e: f4 hlt
17 509f: 90 nopThe middle column (starting with endbr64) shows the x86_64 instruction being performed on that line. The rightmost column contains parameters to each of these operations.
Near the end, we see that the Rust compiler has provided some helpful hints on where execution moves next. At address 0x5091 we see an instruction with an interesting comment to the right: # 53d0 <main>. This is Rust giving us a clue that execution moves to the memory offset 0x53d0. Scrolling down, we can see exactly where this picks up:
100000000000053d0 <main>:
2 53d0: 48 83 ec 18 sub rsp,0x18
3 53d4: 8a 05 8f 56 03 00 mov al,BYTE PTR [rip+0x3568f] # 3aa69 <__rustc_debug_gdb_scripts_section__>
4 53da: 48 63 cf movsxd rcx,edi
5 53dd: 48 8d 3d 0c ff ff ff lea rdi,[rip+0xffffffffffffff0c] # 52f0 <rbin::main>
6 53e4: 48 89 74 24 10 mov QWORD PTR [rsp+0x10],rsi
7 53e9: 48 89 ce mov rsi,rcx
8 53ec: 48 8b 54 24 10 mov rdx,QWORD PTR [rsp+0x10]
9 53f1: 88 44 24 0f mov BYTE PTR [rsp+0xf],al
10 53f5: e8 e6 fd ff ff call 51e0 <std::rt::lang_start>
11 53fa: 48 83 c4 18 add rsp,0x18
12 53fe: c3 ret
13 53ff: 90 nopAgain, we have another hint: # 52f0 <rbin::main>. This time we scroll up to find that address, and in turn, the actual machine code representing our main() function:
100000000000052f0 <rbin::main>:
2 52f0: 48 83 ec 78 sub rsp,0x78
3 52f4: 48 8b 05 8d e2 03 00 mov rax,QWORD PTR [rip+0x3e28d] # 43588 <__do_global_dtors_aux_fini_array_entry+0>
4 52fb: bf 05 00 00 00 mov edi,0x5
5 5300: be 08 00 00 00 mov esi,0x8
6 5305: 48 89 44 24 18 mov QWORD PTR [rsp+0x18],rax
7 530a: e8 81 00 00 00 call 5390 <rbin::sum>
8 530f: 89 44 24 6c mov DWORD PTR [rsp+0x6c],eax
9 5313: 48 8d 35 46 f4 02 00 lea rsi,[rip+0x2f446] # 34760 <core::fmt::num::imp::<impl core::fmt::Display for >
10 531a: 48 8d 44 24 6c lea rax,[rsp+0x6c]
11 531f: 48 89 44 24 60 mov QWORD PTR [rsp+0x60],rax
12 5324: 48 8b 44 24 60 mov rax,QWORD PTR [rsp+0x60]
13 5329: 48 89 44 24 70 mov QWORD PTR [rsp+0x70],rax
14 532e: 48 89 c7 mov rdi,rax
15 5331: e8 4a fe ff ff call 5180 <core::fmt::ArgumentV1::new>
16 5336: 48 89 44 24 10 mov QWORD PTR [rsp+0x10],rax
17 533b: 48 89 54 24 08 mov QWORD PTR [rsp+0x8],rdx
18 5340: 48 8b 44 24 10 mov rax,QWORD PTR [rsp+0x10]
19 5345: 48 89 44 24 50 mov QWORD PTR [rsp+0x50],rax
20 534a: 48 8b 4c 24 08 mov rcx,QWORD PTR [rsp+0x8]
21 534f: 48 89 4c 24 58 mov QWORD PTR [rsp+0x58],rcx
22 5354: 48 8d 54 24 50 lea rdx,[rsp+0x50]
23 5359: 48 8d 7c 24 20 lea rdi,[rsp+0x20]
24 535e: 48 8b 74 24 18 mov rsi,QWORD PTR [rsp+0x18]
25 5363: 41 b8 02 00 00 00 mov r8d,0x2
26 5369: 48 89 14 24 mov QWORD PTR [rsp],rdx
27 536d: 4c 89 c2 mov rdx,r8
28 5370: 48 8b 0c 24 mov rcx,QWORD PTR [rsp]
29 5374: 41 b8 01 00 00 00 mov r8d,0x1
30 537a: e8 c1 00 00 00 call 5440 <core::fmt::Arguments::new_v1>
31 537f: 48 8d 7c 24 20 lea rdi,[rsp+0x20]
32 5384: ff 15 16 0b 04 00 call QWORD PTR [rip+0x40b16] # 45ea0 <_GLOBAL_OFFSET_TABLE_+0x530>
33 538a: 48 83 c4 78 add rsp,0x78
34 538e: c3 ret
35 538f: 90 nopAs you can imagine, there’s a lot to cover here - too much to cover in this post. So we’ll instead look at the instructions that are most relevant to the example code at the beginning of this post. Feel free to take a look at the instructions I don’t cover explicitly - I did, and found it to be instructive.
If you’re new to reading assembler like I am, the good news is there are a lot of guides out there that can help you understand what’s happening here. I found this guide and this summary to be helpful, but there are plenty of others that work well too - just be aware of the assembly syntax you’re using (remember I’m using Intel for this post).
First, we notice at the top of this function’s code, we see the first operation claims 120 (0x78) bytes of stack space. This is common to see at the top of each function’s block of machine code:
152f0: 48 83 ec 78 sub rsp,0x78Recall, our program specifies two integer literals (5 and 8) as parameters to our sum function, so the Rust compiler moves both of these values into the edi and esi registers:
We’re almost ready to call our sum function, but before we can do that we have to do something with the rax register:
By convention, %rax is used to store a function’s return value, if it exists
The return value from sum will be stored in the rax register eventually, but if you look carefully, we’ve already moved a value into rax further up in our main function. So, before we call sum, we should move this value somewhere safe.
Our compiler knows that our sum function will use 18 bytes of stack space (as we’ll see when we look at the code for the sum function), so we can safely move this value into a memory location that is 18 bytes offset from the current stack pointer:
15305: 48 89 44 24 18 mov QWORD PTR [rsp+0x18],rax #TODO Why does this happen before the function call?Finally we can call our sum function:
1530a: e8 81 00 00 00 call 5390 <rbin::sum>Let’s take a look at that memory location (5390) - I’ll again provide the whole assembly for this function, and then explore the relevant instructions in detail:
10000000000005390 <rbin::sum>:
2 5390: 48 83 ec 18 sub rsp,0x18
3 5394: 89 7c 24 10 mov DWORD PTR [rsp+0x10],edi
4 5398: 89 74 24 14 mov DWORD PTR [rsp+0x14],esi
5 539c: 01 f7 add edi,esi
6 539e: 0f 90 c0 seto al
7 53a1: a8 01 test al,0x1
8 53a3: 89 7c 24 0c mov DWORD PTR [rsp+0xc],edi
9 53a7: 75 09 jne 53b2 <rbin::sum+0x22>
10 53a9: 8b 44 24 0c mov eax,DWORD PTR [rsp+0xc]
11 53ad: 48 83 c4 18 add rsp,0x18
12 53b1: c3 ret
13 53b2: 48 8d 3d 57 0c 03 00 lea rdi,[rip+0x30c57] # 36010 <str.0>
14 53b9: 48 8d 15 d0 e1 03 00 lea rdx,[rip+0x3e1d0] # 43590 <__do_global_dtors_aux_fini_array_entry+0x60>
15 53c0: 48 8d 05 b9 ad 02 00 lea rax,[rip+0x2adb9] # 30180 <core::panicking::panic>
16 53c7: be 1c 00 00 00 mov esi,0x1c
17 53cc: ff d0 call rax
18 53ce: 0f 0b ud2 As was done with the main() function, and as alluded just previously, this function allocates 18 bytes of stack space:
15390: 48 83 ec 18 sub rsp,0x18Next, we move the values in the edi and esi register, which - if you recall from the main function - store the parameters for our sum function. A few things to note here - the memory offsets rsp+0x10 and rsp+0x14 are both within the stack space we’ve allocated. In fact, there’s enough room for each location to store a 4-byte value. This makes sense, because both should be exactly that - 32 bit integers!
Next, we add these two values. This operation works by adding the value of the second operand into the first, so after this operation completes, edi will no longer represent one of our parameters, but rather the the result of our addition operation:
1539c: 01 f7 add edi,esiNext, we move the result of this operation now stored in edi into stack space, and then again from there into the eax register
Finally, we can hand back our stack space and return to the calling location within the main function:
Back out at our main function, the operations immediately following our call to sum move the result stored in eax into stack space, and then from there into the rax register.
This was a very limited-scope look at the numerous operations generated by the Rust compiler for what on the surface looks like a very simple operation. Imagine what a complex application must look like! There were plenty of other cases that we didn’t cover, such as those that result in a program crash, so please take the time to use the commands I’ve shown above to look at your own code and learn.
This was a bit of a journey, but hopefully you stuck with it, and learned as much as I did! In summary:
The actual executable format itself is ELF. There are many different formats, but this is a very common one in Linux-based operating systems. There is a tremendous amount of metadata contained within a binary executable that is easily inspected using readily available tools.
The actual machine code is x86 machine code. This instruction set is supported by many hardware platforms, and it is for this reason it is thought to be “hardware independent”. This just means this instruction set isn’t only usable on a specific kind of hardware, but is broadly accepted and supported.
The interpretation of the binary instructions (as hexidecimal opcodes) is Intel. This is less meaningful for the computer and more meaningful for me, as there is no “intel vs att” at the machine code level. This is just an interpretation that allows us to make machine code a bit more readable and writable.
The actual executable code that get placed into the binary, is all up to the compiler. As we’ve seen, even a simple example results in quite a bit of machine code. We did a pretty simple operation, and only worked with stack memory allocations, which are handled pretty well by the compiler. Heap allocations are a bit more complex and require coordination with the operating system. You can imagine that the compiler has to do a lot of work to just get a viable program - never mind all of the additional checks that something like the Rust compiler does to keep us safe from all kinds of memory handling issues. Try disassembling a more complex program and try to follow the various branches of logic through the underlying assembly!
I linked to some helpful resources throughout this post, but here are a few others that I thought were useful that didn’t make it into the contents above: